(4/4) Pidgeot: a system for millions of documents; Testing and Conclusions
Date:
You can read the previous part here: (3/4) Pidgeot: a system for millions of documents; Deploying and Scaling
Thanks to the work we did previously, we have everything we need for actually testing this system in place:
- we have set up PostgreSQL and MinIO for storing millions of documents
- we have a Java API to test how well accessing this data works
- we are now running in the cloud, with 10 million file versions
- we also have 2 instances of the above setup, one with PostgreSQL table partitions and one without
How to test
Figuring out how to test and what we want to test is actually the hard part here. Some might be tempted to just run load tests against something like this and it's not like I disagree with such an approach. I've successfully used K6s in the past, for my Master's degree.
Yet this time, I care a bit more about how individual requests are served, how quickly document versions and such can be returned, how quickly data can be looked up,how it actually looks under the hood and whether partitions are actually useful or not.
For something like that, starting out with testing the web API seems like the reasonable thing to do, which also has the added benefit of being both realistic and easy.
Setting up for testing the web API
For this, we'll use Postman, a program for interacting with APIs. I do think that it's kind of clunky, but also is generally passable. First, we want to import all of our endpoints, which I achieved with taking a list of URLs and some text manipulation, as well as a Bash script to split them into a file per URL:
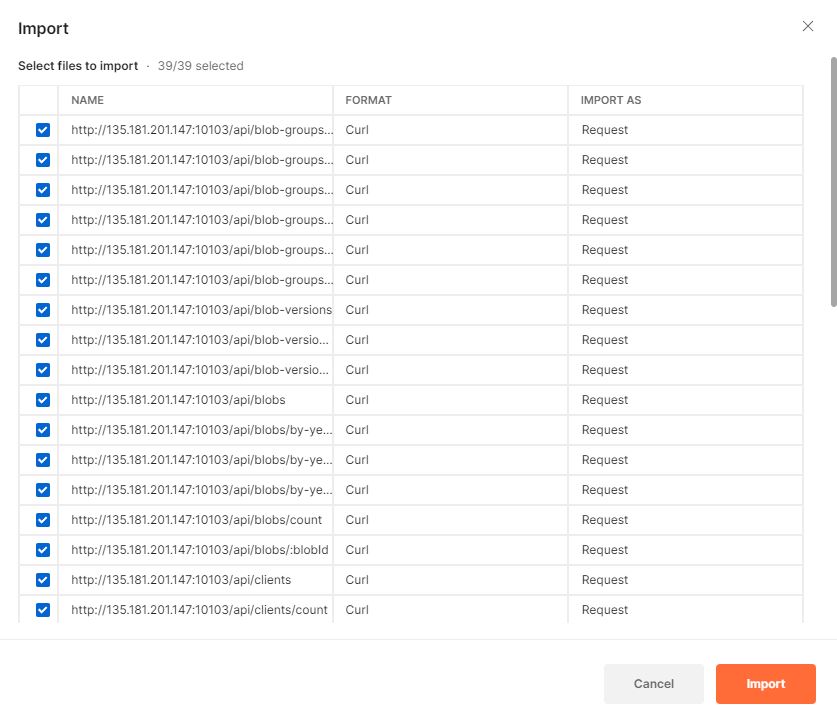
(this took a bit of off-screen work and admittedly going for generated OpenAPI specs would have been ideal, although writing those manually is a bit of a pain)
From there, I could execute any of the API endpoints across either of the two instances, which run on the same server in parallel, but consume very little resources when idle, so can generally be tested in a staggered manner:
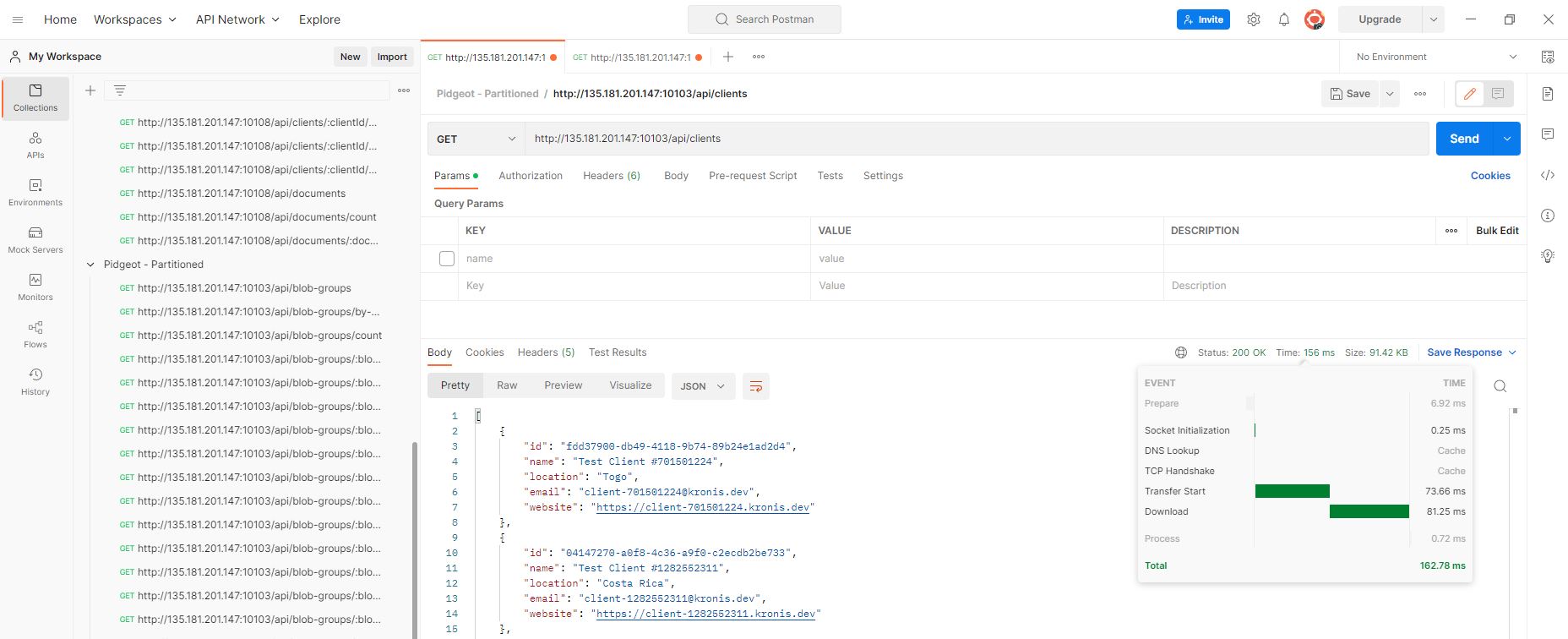
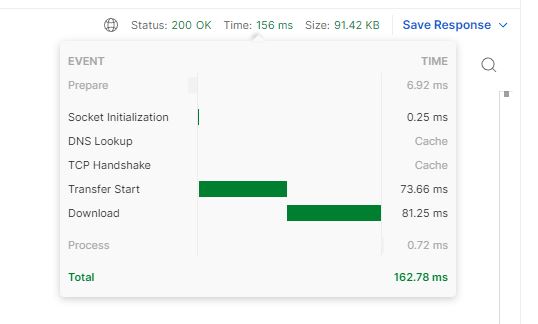
The nice thing is that not only can we preview the results, but we also get information about the request timings, how much time was spent sending data through the network, as well as how much time was spent waiting for the server to process our request:
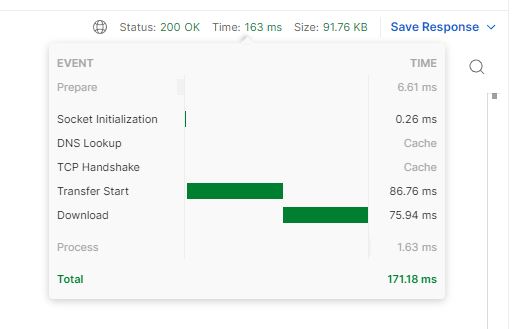
This also lets me compare similar requests across both of the instances, to see if partitioned and non partitioned ones have different performance characteristics. For example, in this case both are more or less equal, because the clients table has no partitions:
We'll dig in more into the database side of things later, but for now we have a nice setup to start out with for checking whether there are any significant differences in how the API instances perform.
Testing the web API
I don't actually intend to check every single endpoint, but I'm curious to see whether their performance is consistent, so I'll go through quite a few that are of interest to me.
Client search
First, let's look up a client by their name, picked from an existing random record in each database. Here's how that looks for the partitioned instance:
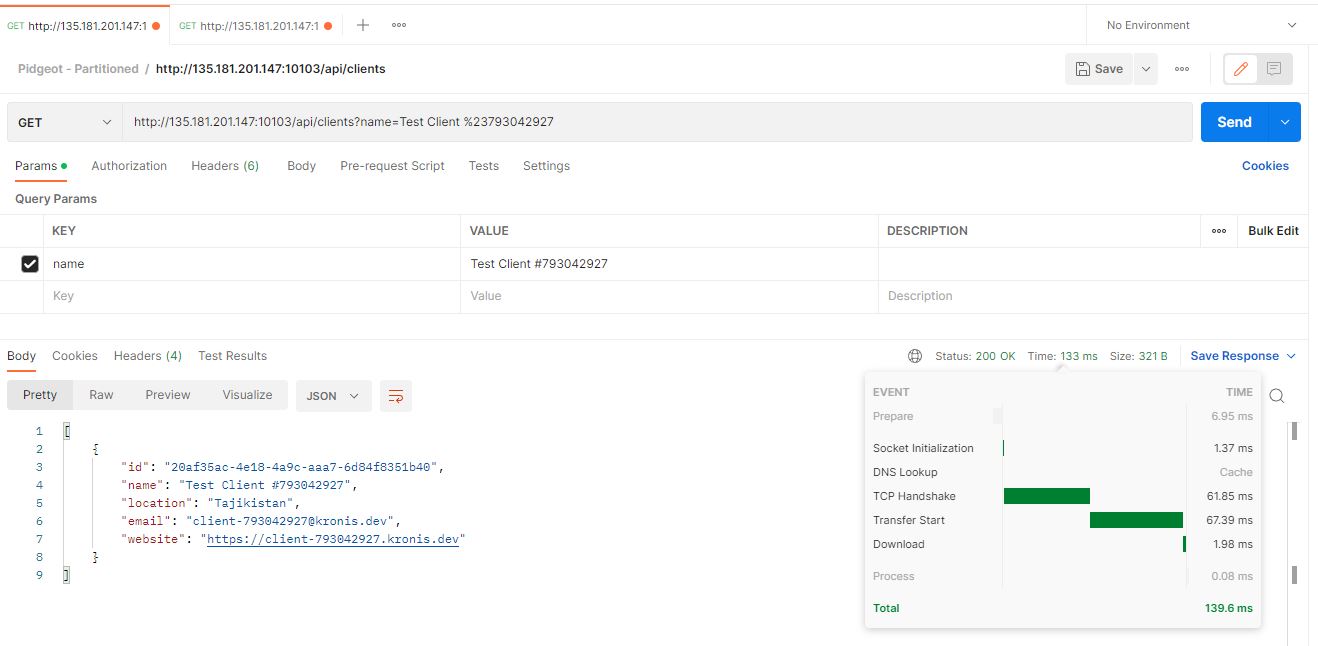
Here's how that looks for the non-partitioned instance:
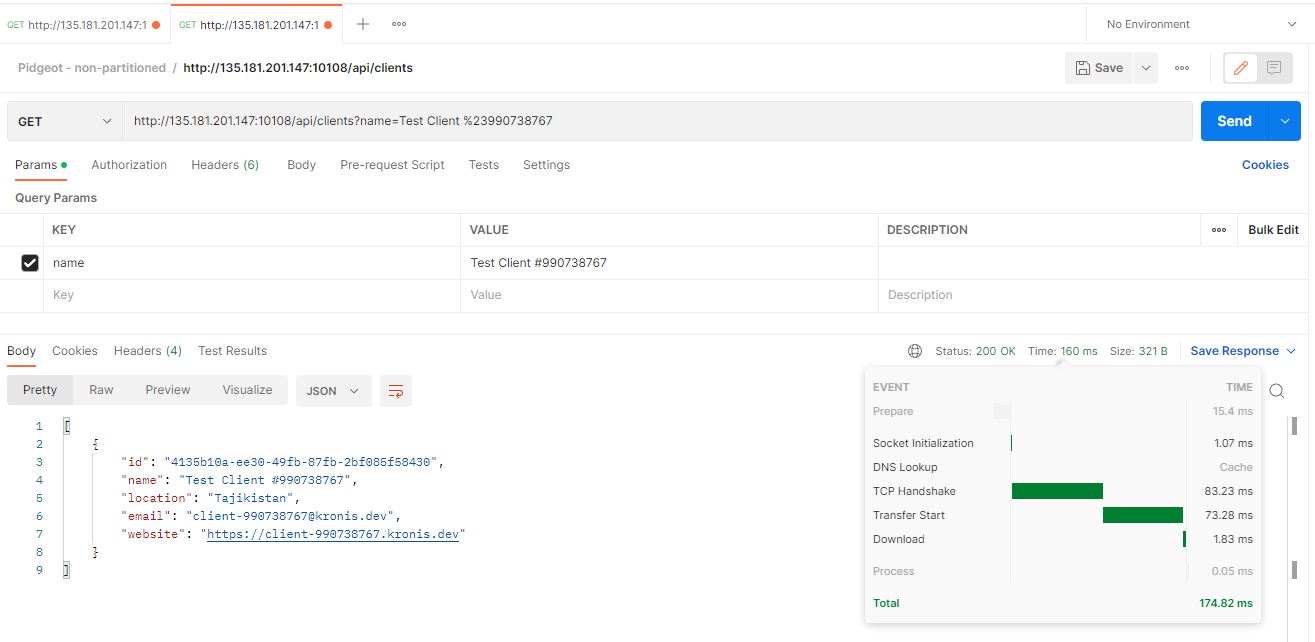
There seem to be small differences in these times occasionally, but seeing as the request is processed on the server side in either 60 or 80 milliseconds, it's probably nothing too substantial.
Documents for a client
Then, let's list all of the documents for a client, something which does generate a little bit more data, coming in at whopping 20 KB.
Here's the partitioned instance:
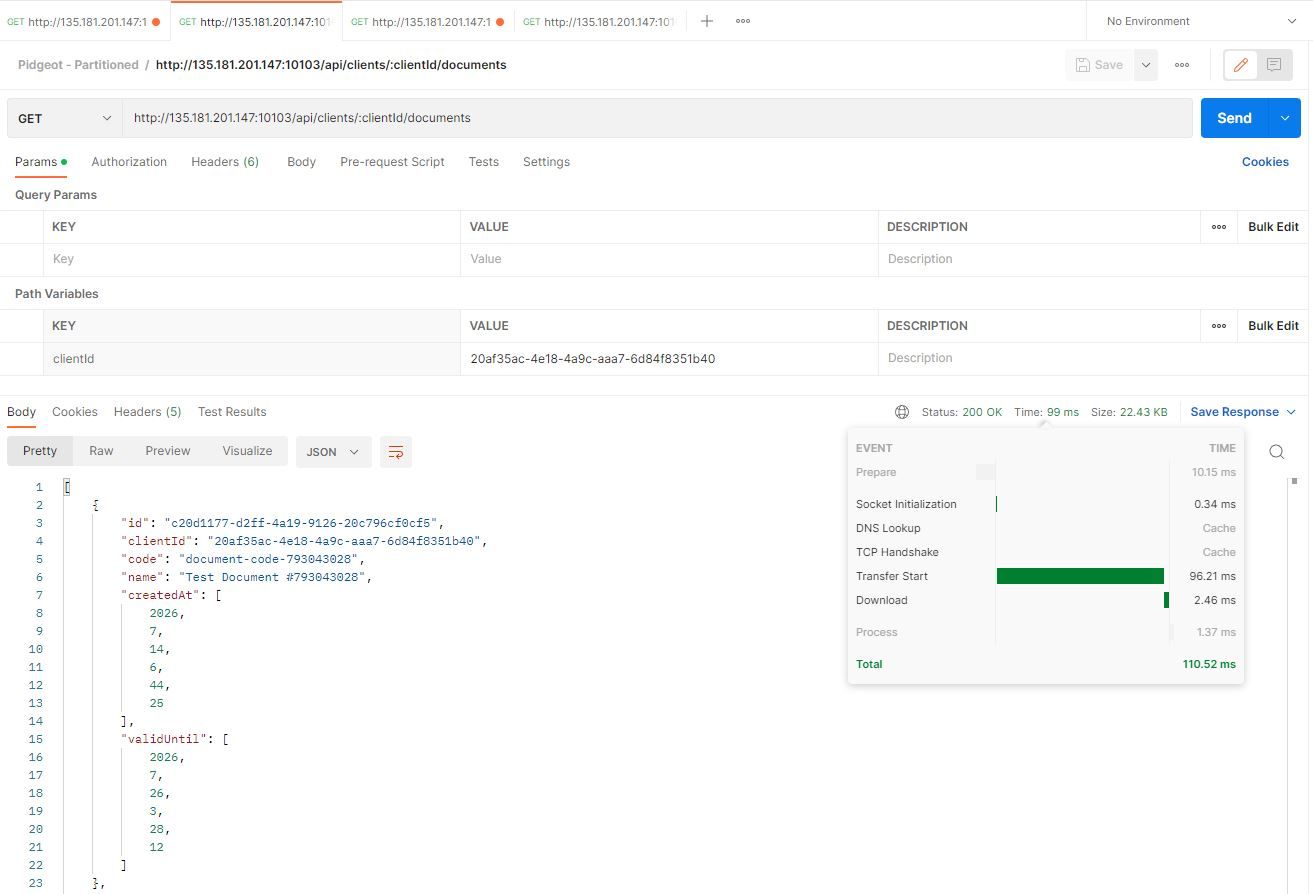
Here's the non-partitioned instance:
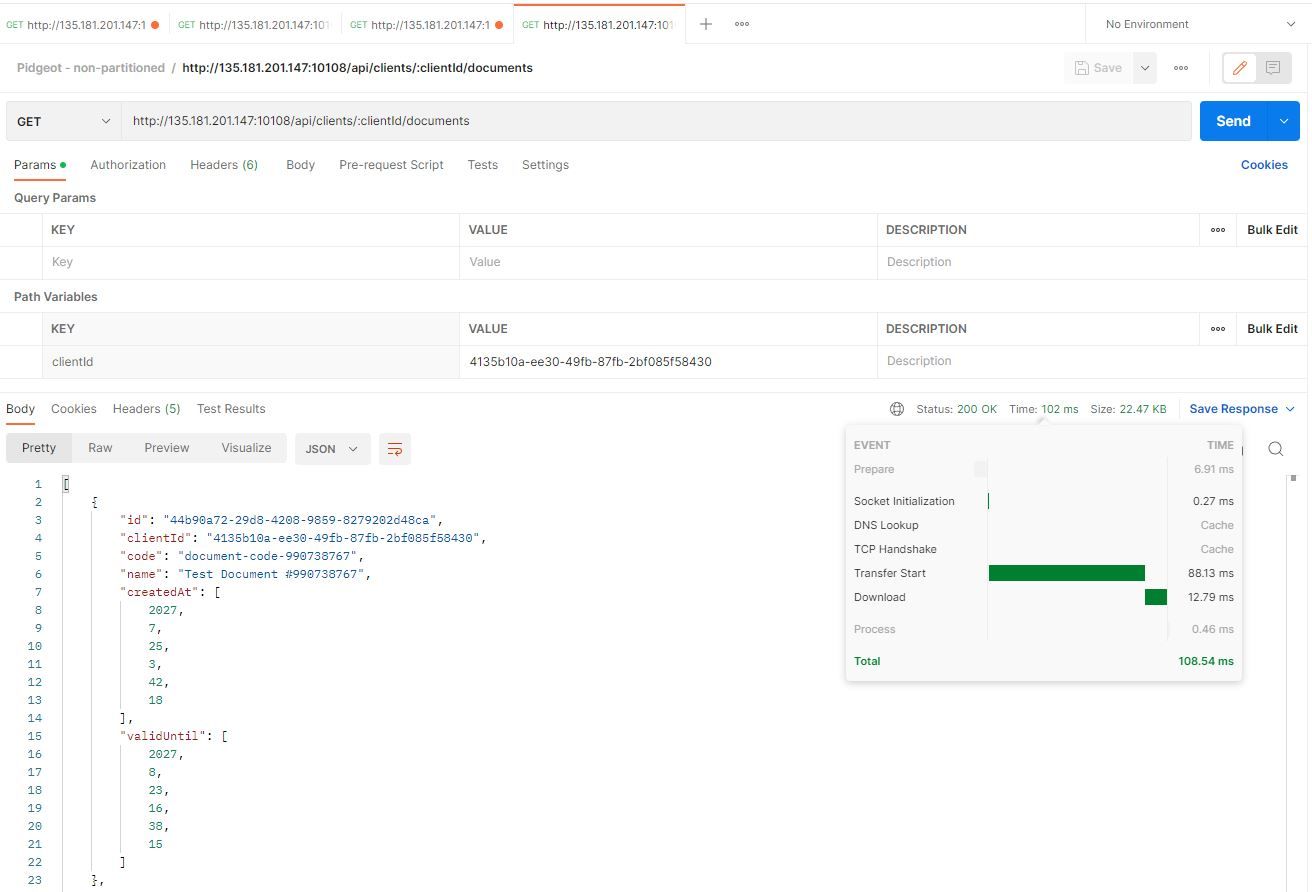
Once again, we're getting similar results, since even though the generated data has different UUIDs in the various instances, the actual amounts of data to iterate through are similar.
Blobs for a document
Next up, let's get all of the blobs for a given document, checking what working in a more specialized system would be like. If our system worked with more than just blob groups, blobs and versions, we might have to query based on linked data like this.
Here's the partitioned instance:
Here's the non-partitioned instance:
Once again, close enough.
Blobs for a document, per year
Let's see whether using the endpoints that are meant to select data by the year will have a bigger effect on performance! Here's where I think that we might see a bigger difference, since the smaller partitioned tables should reduce the total amount of data to check.
Here's the partitioned instance:
Here's the non-partitioned instance:
This time, the partitioned instance seems to do a little bit better, but not to the point where I could say that it's in a clear lead. They're both still doing very well and any differences might just be random noise, since a difference of 20 milliseconds across different requests might as well be random noise.
Blob versions for blob and group
The partitioned instance also seems similarly faster for accessing blob versions for a particular blob group and blob in it. Faster, but not enough so for it to matter.
Here's the partitioned instance:
Here's the non-partitioned instance:
Latest blob version for blob
The same trend is also present when we try to recover the latest version for a particular blob, out of all of them.
Here's the partitioned instance:
Here's the non-partitioned instance:
Specific blob version for blob, per year
Okay, so how complicated can we make this? How about selecting a specific blob version for a given blob and blob group, in a certain year? Surely this should make the partitions do something and improve how well it works? Right?
Here's the partitioned instance:
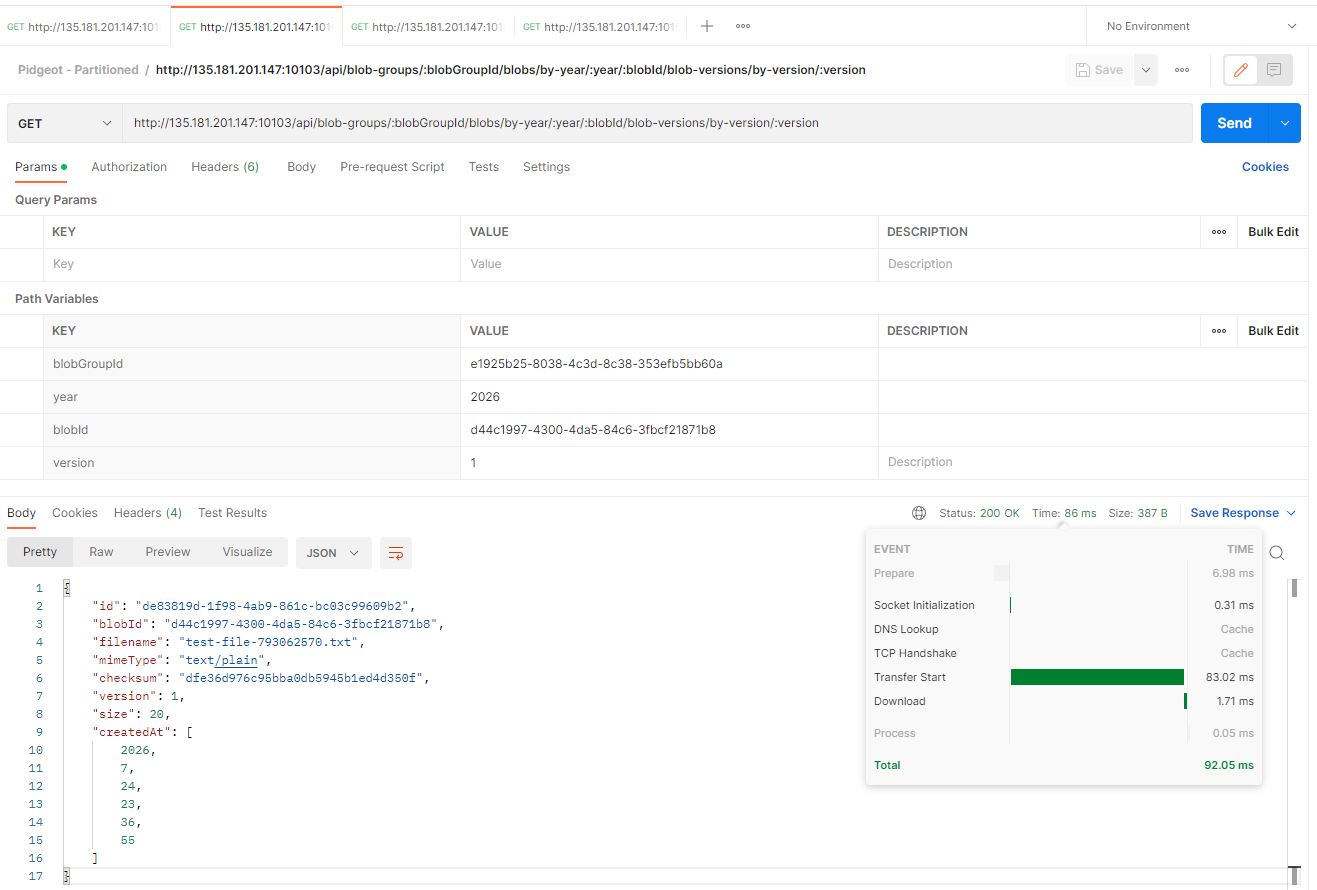
Here's the non-partitioned instance:
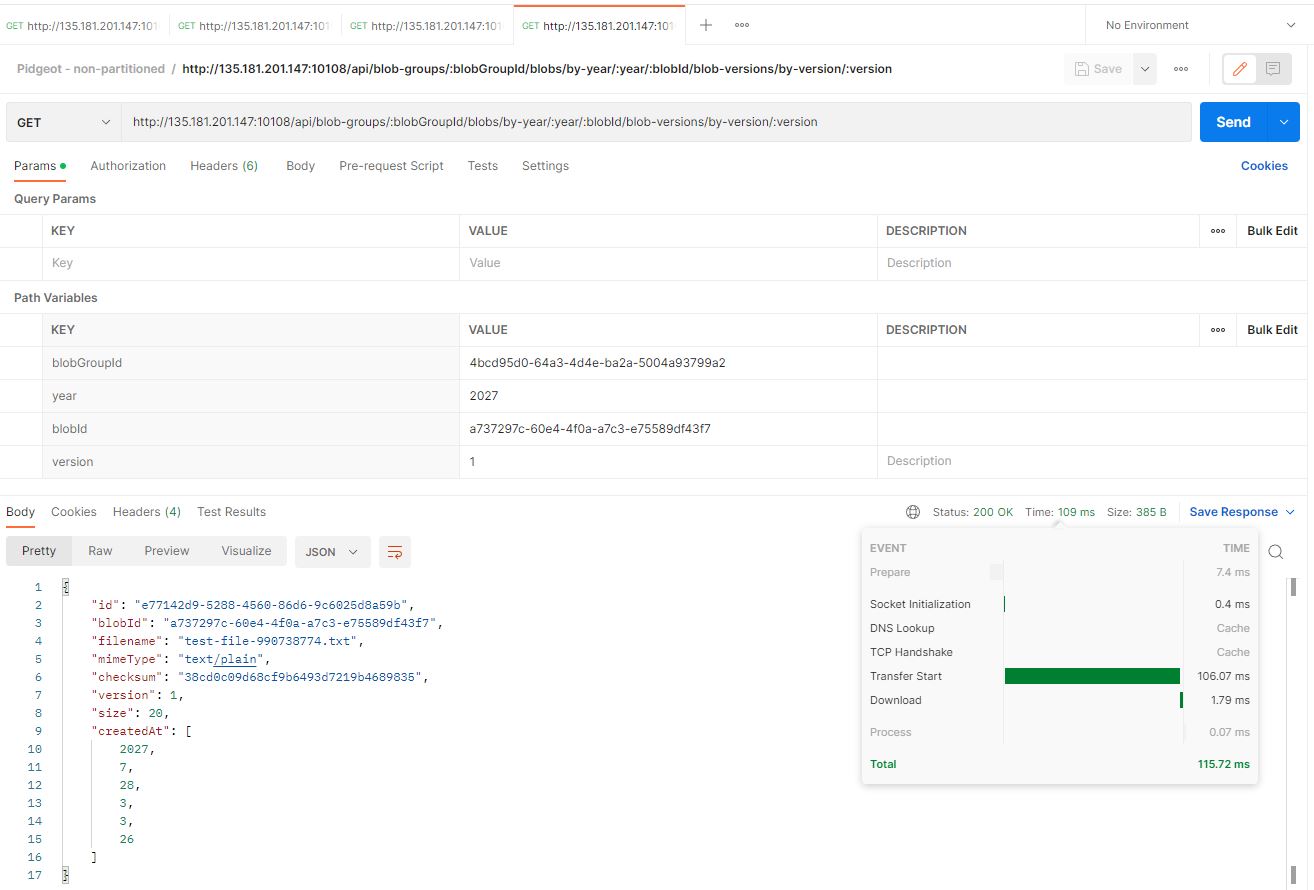
Have you ever worked on something for multiple days, expecting for it to yield some sort of a payoff in the end? To be able to point at the results and go: "So, here we prove that you need database partitions for these reasons, they have the potential to slightly improve performance even when the partitions are on the same physical device, when you can filter your data by the partition key, because only that partition table will need to be processed."
Except that none of that happened. Actually, as far as I can tell after testing the web API, it's more like: "Unless you're working with hundreds of millions of records, partitions won't matter all that much... because PostgreSQL is amazing as it is and with a properly normalized DB schema it'll go far as it is."
So, in a few words, I'd describe my assumptions so far as: "Task failed successfully!"
Testing the database
But why?
A non-optimized query
You know, at this point it's nice to write some more useful queries for checking how things actually work on the database side. First, a "non optimized query", that joins the tables that we have and looks for data for a given client:
/* non-optimized query */
SELECT *
FROM clients
INNER JOIN documents
ON documents.client_id = clients.id
INNER JOIN blobs
ON blobs.document_id = documents.id
INNER JOIN blob_versions
ON blob_versions.blob_id = blobs.id
WHERE
clients.name = 'Test Client #793042927';Here's the partitioned instance:
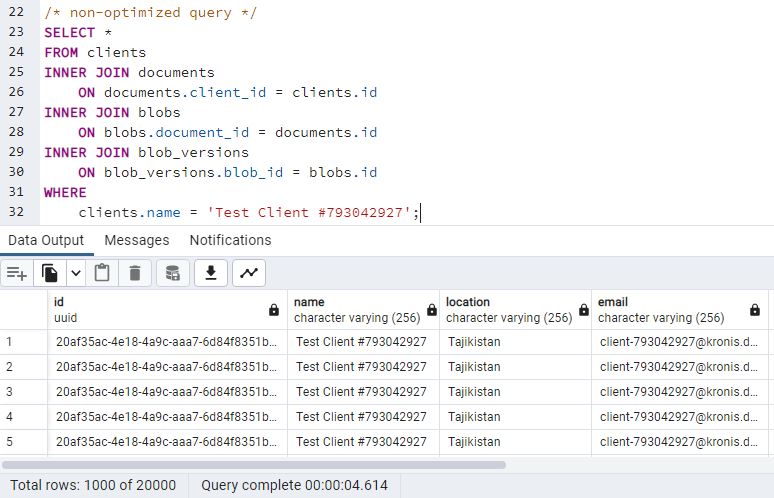
Here's the non-partitioned instance:
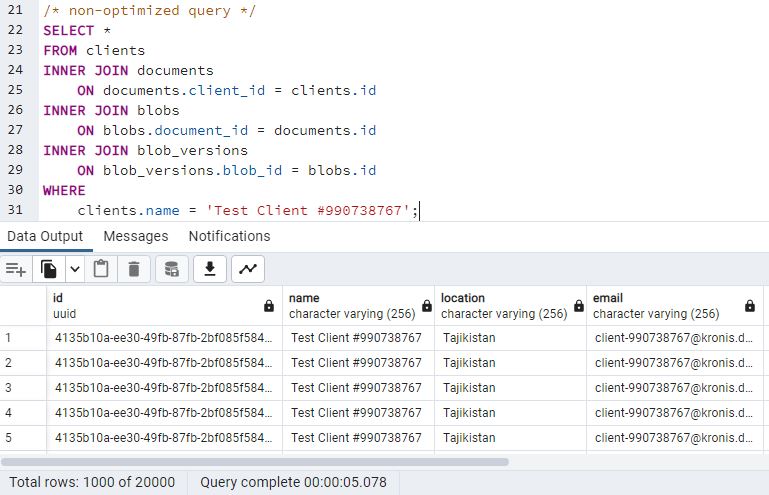
So, the total query times are getting longer, but there's still a 0.5 second difference between the two instances, not enough to be significant. Also, remember that we're fetching around 20'000 rows here.
An optimized query
Okay, suppose that we could query the data in a way that should work a bit better with our table partition setup. If we only want to get data for a particular year, surely the instance with the partitions should be more performant:
/* optimized query */
SELECT *
FROM clients
INNER JOIN documents
ON documents.client_id = clients.id
INNER JOIN blobs
ON blobs.document_id = documents.id
INNER JOIN blob_versions
ON blob_versions.blob_id = blobs.id
WHERE
clients.name = 'Test Client #793042927'
AND EXTRACT(YEAR FROM blobs.created_at) = 2029;Here's the partitioned instance:
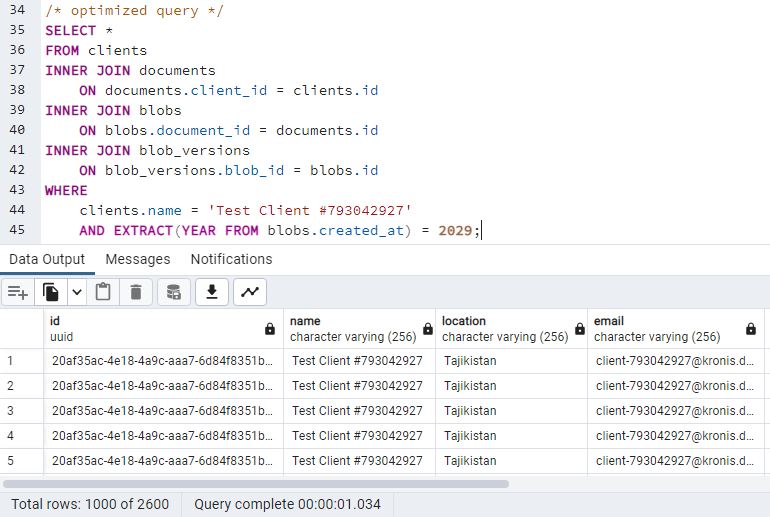
Here's the non-partitioned instance:
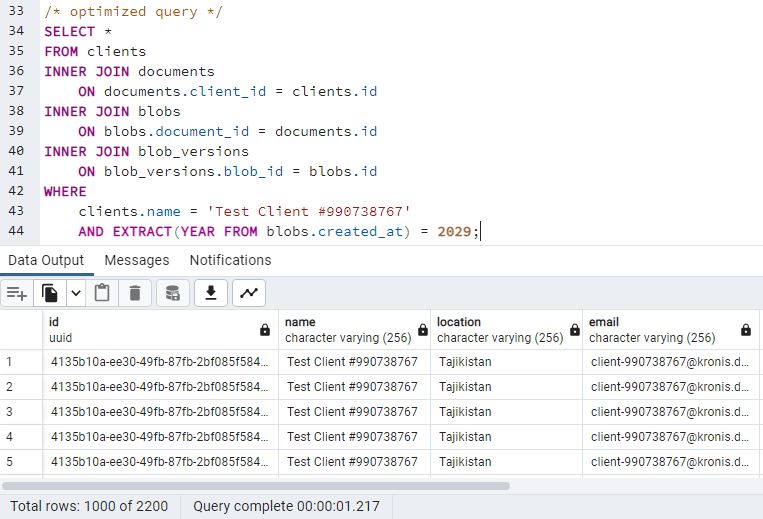
So, that assumption was demonstrably wrong. They perform basically the same, even when the partition key ensures that you should be able to work with 10x less data in one of the cases.
A partition query
Okay, so what if I was to query the partition table directly, when I know in which partition the data is and also can generate the SQL for my own needs:
/* partition query */
SELECT *
FROM clients
INNER JOIN documents
ON documents.client_id = clients.id
INNER JOIN blobs_2029
ON blobs_2029.document_id = documents.id
INNER JOIN blob_versions
ON blob_versions.blob_id = blobs_2029.id
WHERE
clients.name = 'Test Client #793042927'
AND EXTRACT(YEAR FROM blobs_2029.created_at) = 2029;Please note, that this would mean that I'd need to be able to dynamically generate the SQL, so the JDBI3 annotation approach might not work and instead I'd need something like myBatis.
So here's the partitioned instance results, since the non-partitioned doesn't have the table and we can only test it here:
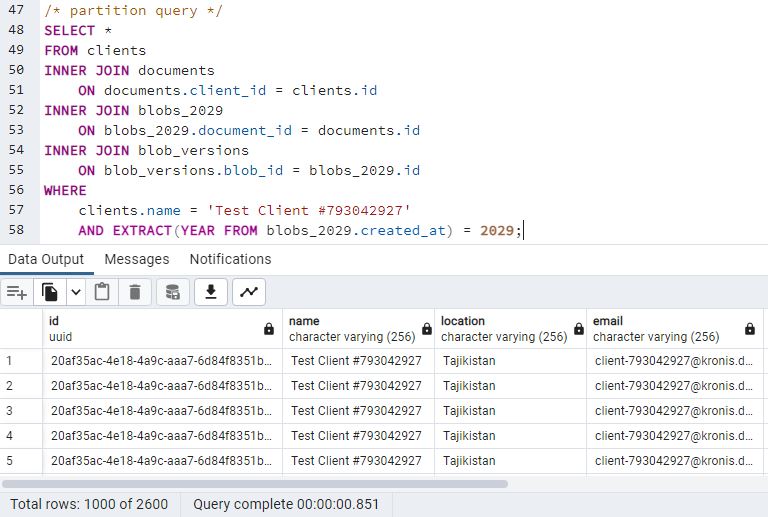
If you squint, it seems slightly better, but not the 10x gain in performance that I expected. Even more so, the actual blob version access means working with a table that has 10 million records in it. Surely when we already know which blob we are going to work with, finding the records in a table that has many times less data should be easier, even with indexes?
Not really, or at least we haven't hit that scaling limit, so both of the instances seem to perform the same. We should proceed with seeing how the queries are planned and whether my assumptions about table partitioning are anywhere near correct.
Exploring the database
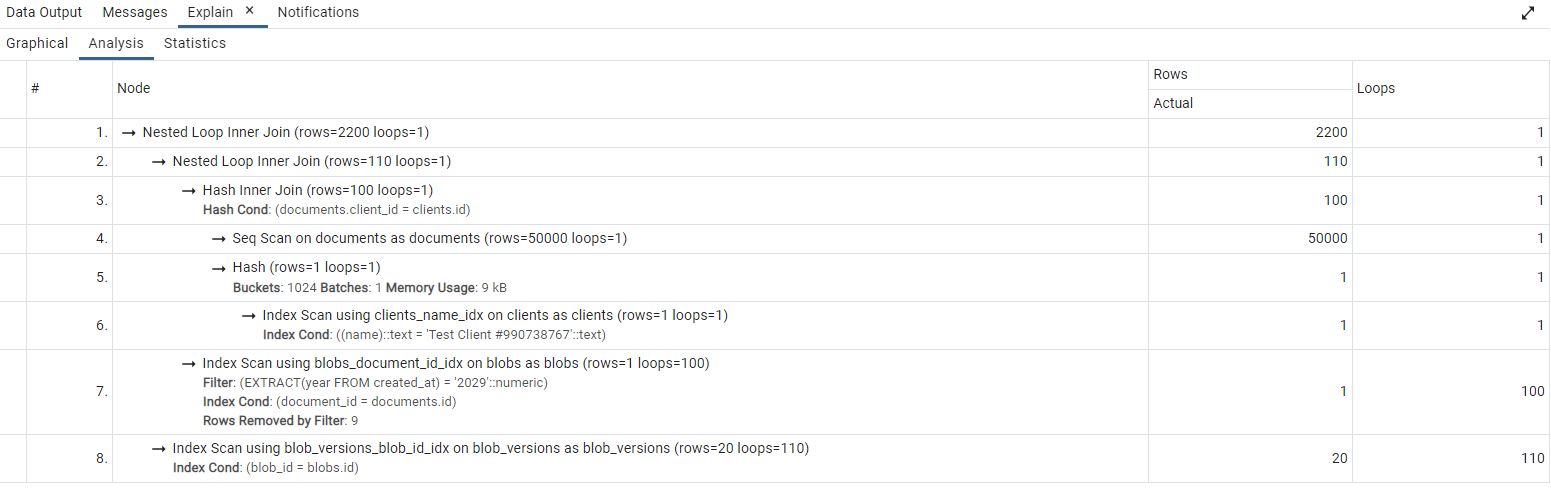
Thankfully, we can explore the plans for the queries and see how the partitions help us, or actually do the opposite. This time, first let's look at how the "optimized query" looks for the non-partitioned database instance:
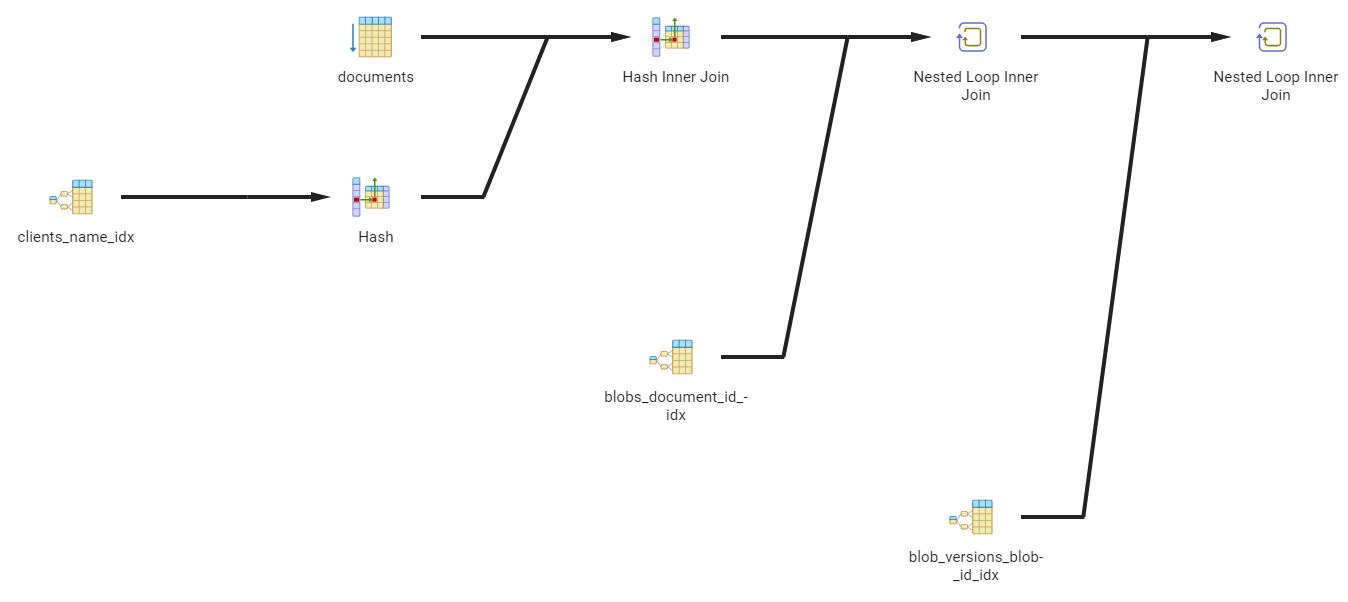
So, it's pretty simple: we have an index for the client name, we have an index for the document id, we have an index for the blob id. Pretty straightforward.
Now, here's how the partitioned version looks:
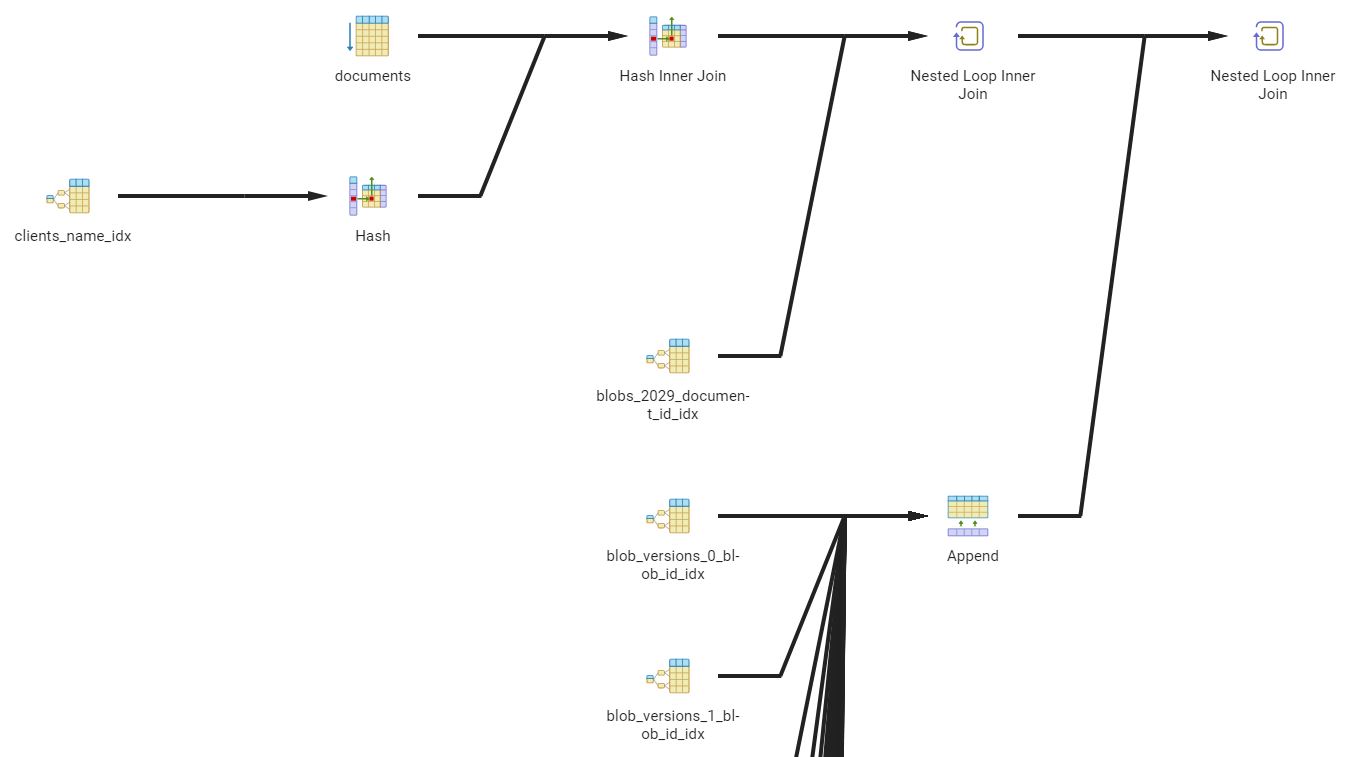
(image cropped vertically for readability)
This instantly looks a little bit more suspicious. The good news is that our document index is currently used on the partition table for the particular year: 2029 in this case. However, then we get to working with all of the partitions that have blob versions in them based on the first letter of the related blob id... and we query a lot of the tables.
It then becomes apparent that how we're querying the data won't lead to all that many optimization benefits - because while we select the data for a given client and year, it's not like that has anything to do with the randomly generated blob id values.
In this case, the only real benefits from this partitioning scheme that we might get have to do with how they could be stored and distributed across different disks, for a form of load balancing.
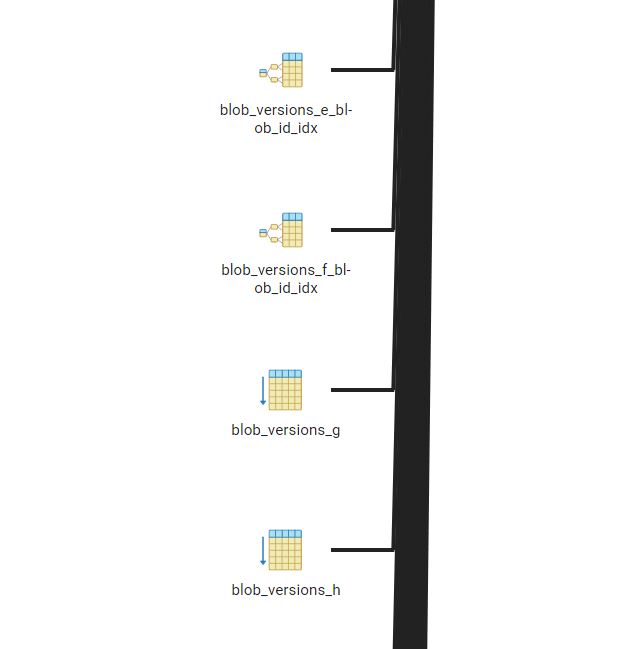
Also, curiously you can see where the actual values in the tables end and where empty tables begin, indices no longer being relevant for the latter (which is because I decided to demonstrate creating tables for every letter in the alphabet, since other kinds of storage schemes might benefit from that):
Asking the database to explain the plan also tells us more about how all of this works, for example, here's the non-partitioned instance again:
And here's the partitioned instance:
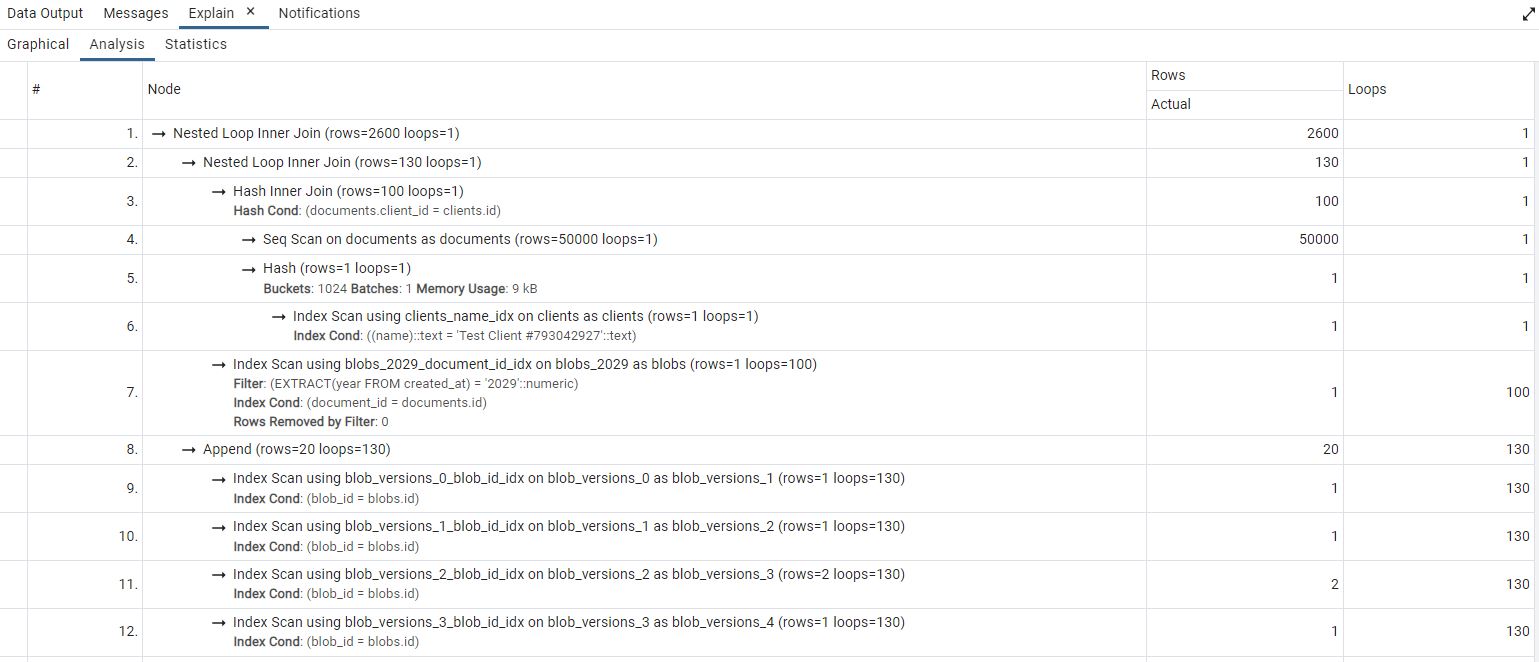
The table actually ends up even longer, but I've cut off the bottom for space reasons. In short, there are lots of individual index scans going on here. Also, it would appear that we've processed 50000 documents in our query, so it's interesting how we're able to return data so quickly!
In cases like this, we might benefit from composite partitioning also having blob version partitions based on year and then also by the first letter of the blob, if need be. Of course, we'd only actually need to explore such options if we actually worked at a scale where that became relevant.
But for now? Our current approach is enough and could even be simplified, or we could have the year as the only type of partition we use for now, since that seems like a good fit for the domain.
What about the actual files
I actually have gotten to a point where most of my questions about how this sort of a system performs have been answered, except that I didn't actually do that many file downloads. For actually doing it I'd also need to introduce an actual web UI (for convenience) and figure out the whole download URL question.
But the question here is whether I really need to do that. I already know that MinIO works as an S3 implementation and can get any of the millions of files through Cyberduck:
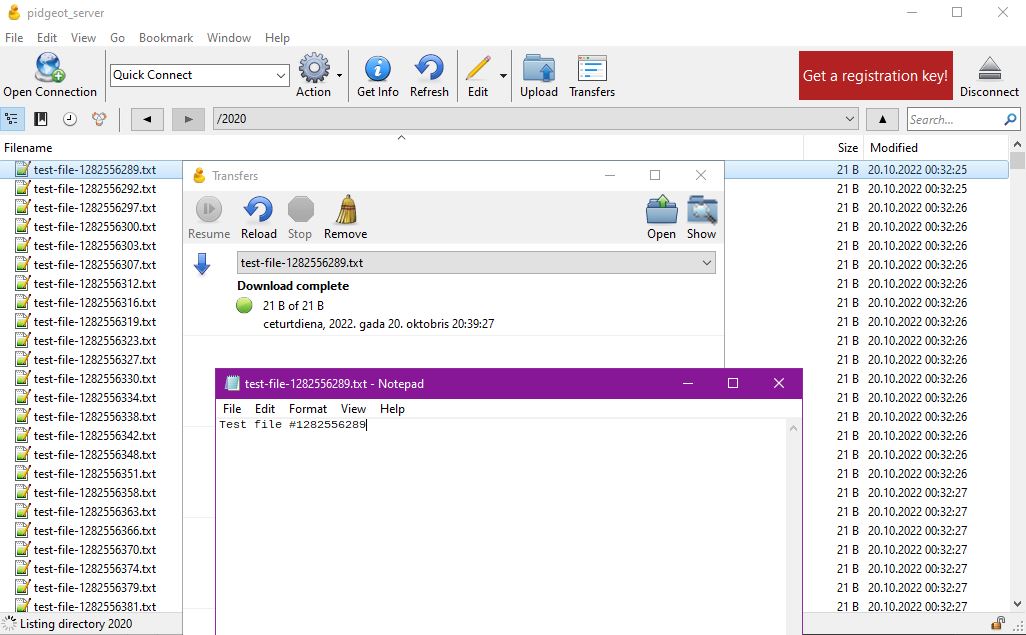
The rest would just be an implementation detail, except that this series of articles has already gotten pretty long and I feel satisfied with my findings.
So for now, that's good enough.
Summary
It seems like there are actually quite a few things that we can learn from this series of blog posts.
About system design:
- you don't need too much in the way of resources to build a scalable and performant system
- having a set of stable building blocks is pretty good and will let you keep things simple
- using solutions that are popular in the industry is a must for a smooth experience
About PostgreSQL:
- PostgreSQL can scale pretty far, even without doing anything special in it
- data normalization and some relevant indices can definitely help it work even better
- table partitioning isn't talked about as much as it should be... but it's also not always necessary
- it won't always have as many performance implications, as it will help you better organize data
- pgAdmin is still really good tooling, the query plan explanations are some of the better ones I've seen
- having clearly understandable error messages that are meant for humans is helpful, too
- PostgreSQL is perhaps one of the better examples of why you should depend on open source software
About MinIO:
- MinIO works decently as an S3 compatible blob storage solution
- mind your inodes, though, ideally have some alerting set up for those
- also, consider how much storage you'll actually need for all of your files
- the documentation could be better, it might need more options (e.g. public URL for signed links)
About Dropwizard:
- Dropwizard is a decent micro-framework for web application development, simpler than Spring
- it can scale pretty far and also let you implement whatever logic you want for your own needs
- that said, some of the integrations are less convenient (e.g. DI/IoC with HK2)
- JDBI3 works well, but codegen just isn't there yet, nowhere near Ruby on Rails level (nothing is)
- Java is just one of the options for getting things done, .NET, or even Node or Python would work
- whatever framework or language you use, scaling horizontally is a good idea in the current year
- furthermore, consider using feature flags and having separate instances for scheduled processes
About DevOps:
- containers are still an excellent way of making portable software packages
- they integrate nicely with CI/CD, which I'd say is a great quality of life improvement
- being able to get a cloud server and have workloads running on it minutes later is great
- actually, I could say the same about being able to use cloud technologies when you need more resources
- still, pay attention to monitoring your nodes themselves (e.g. Zabbix) and IO/CPU/RAM resources
- XFS feels pretty great, inode limits are a practical reason to check out alternative file systems
About testing:
- there are many types of testing and sometimes even something simple will let you get a good overview
- never take your own assumptions for granted, though (e.g. how things should be queries with partitions)
- ideally, don't be afraid to drop to a lower level of abstraction to understand how things work
And finally, I'd like to show you how much the cloud server that I used for this project cost me:
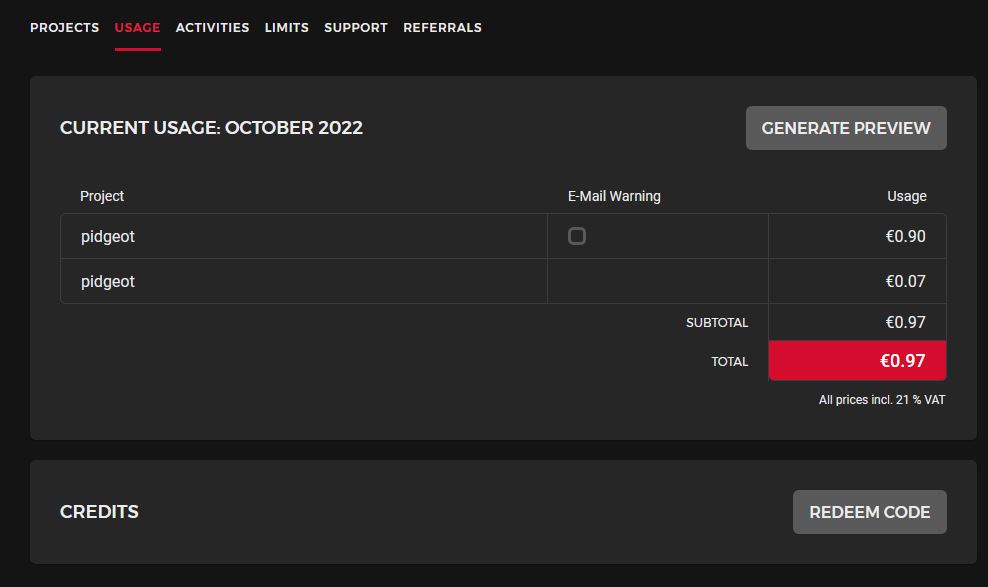
You could have a system that could easily handle tens of millions of records for less than 30 euros a month (development costs or failovers, or load balancers aside). If you wanted to store larger files, you'd still primarily would be storage bound and would need to invest primarily in larger volumes.
I could probably do the same on my homelab for just the cost of electricity if I wanted to, with some reformatting of my drivers to a different file system, and some optimization effort. Much of that thanks to free software; I'm just standing on the shoulders of giants here.
But do consider this - while someone out there might struggle to have something like this working in proprietary technologies as a part of some monolith, I could cook all of this up in a few evenings, thanks to unhealthy amounts of coffee (jokes), though it definitely could be extended further, outside of the scope of just a little research project.
There is no doubt about modern development practices providing a competitive advantage. Also, personally I'm glad to have actually checked that something like PostgreSQL (and MinIO) are indeed well suited for a setup like this.
Other posts: « Next Previous »