How to organize your issue dependencies in Jira
Date:
Let's suppose that you're a developer that is using Jira. A new sprint has just started and you will be able to start working on the issues that you've selected for it, alongside your colleagues. But oh noes, the sprint seems rather big in scope and the issue links section is looking like this for most of the issues:

After seeing something like that, you have no idea where to actually start, since everything seems to depend on everything else. Perhaps you even feel like there's a possibility of there being circular dependencies that somehow got confirmed and put into the sprint, because noone actually cared to check (or didn't know how to).
Now, sometimes online you'll find examples of lists of tasks looking like this:
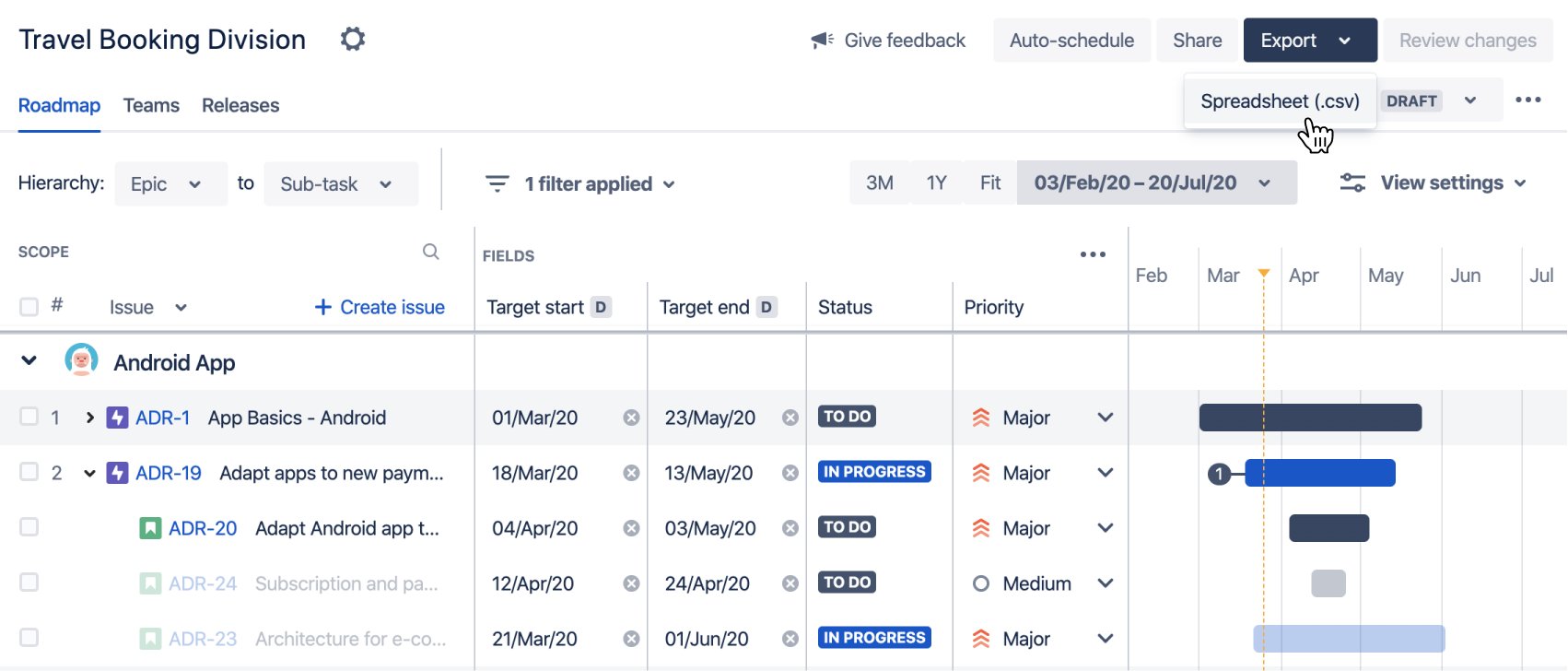
In these cases, the tasks have clear start and end dates (well, at least as far as the planning goes) and in those cases you can make something similar to a Gantt chart. Sadly, this doesn't always coincide with reality! In my company, as well as in many others, people only have an approximate idea of how long any individual task will take, not plan it all out, especially since that would take even more time and clients don't enjoy waiting that much. So, in reality, roadmaps are often impossible to do on a granular level, apart from figuring out which sprints should be done first.
So, what can you even do about situations like this?
Now, normally i'd hope that Jira supports this sort of functionality, but this appears not to be the case, since this doesn't appear to be available in all versions of Jira, though there is some weirdness in the Dependencies report page in the documentation anyways. Essentially i didn't get a clear answer after glancing at the pages, however after digging through our corporate Jira instance, i didn't find any views or functionality like described there. Thankfully, that's not a show stopper for me!
Jira Issue Dependency Grapher
Fear not, Jira Issue Dependency Grapher is here! It's a tool in Python that i wrote with the purpose of being able to visualize these dependencies and perhaps even detect some issues a lot easier! Essentially all of this was possible, because Jira allows using its REST API and there's even a Python library for it:
Now, while writing this tool, i did run into some issues, for example, the fact that there are some problems with using the Personal Access Tokens that the self-hosted variety of Jira supports, which lead to things not working quite like they should at first, despite everything being okay on Jira's side:
Thankfully, that was easy enough to fix, so now, you can get the software in my GitLab instance!
Essentially, you check out the repository, install all of the dependencies and then fill out the .env file with your own parameters:
# the JIRA_URL is where your Jira server lives
JIRA_URL=https://jira.yourcompany.com
# we use your e-mail as the username when using token auth
JIRA_USERNAME=firstname.lastname@yourcompany.com
# we need your access token (NOT your password) to access Jira
JIRA_ACCESS_TOKEN=12345678912345678912345678912345678912345678
# decide between SIMPLE and ORDERED, or ORDERED_MARK_LOOPS draw modes
DRAW_MODE=ORDERED_MARK_LOOPS
# line styles from https://matplotlib.org/stable/gallery/userdemo/connectionstyle_demo.html
CONNECTION_STYLE=arc3,rad=-0.4
# finally, specify which issues you want to find by the query
JIRA_SEARCH_QUERY=project in (YOURPROJECT)There is no GUI for the time being, but that only lends itself better for the tool being easily automatable. Once you run it, it's going to connect to Jira, retrieve the issues that you've filtered by the JQL query, after which it will build a dependency graph in memory based on the has to be done before link type. Once all of that is done, the tool is going to spew this data into the NetworkX library and finally visualize all of it with matplotlib.
Essentially, all of that will result in a pretty and easily understandable graph:
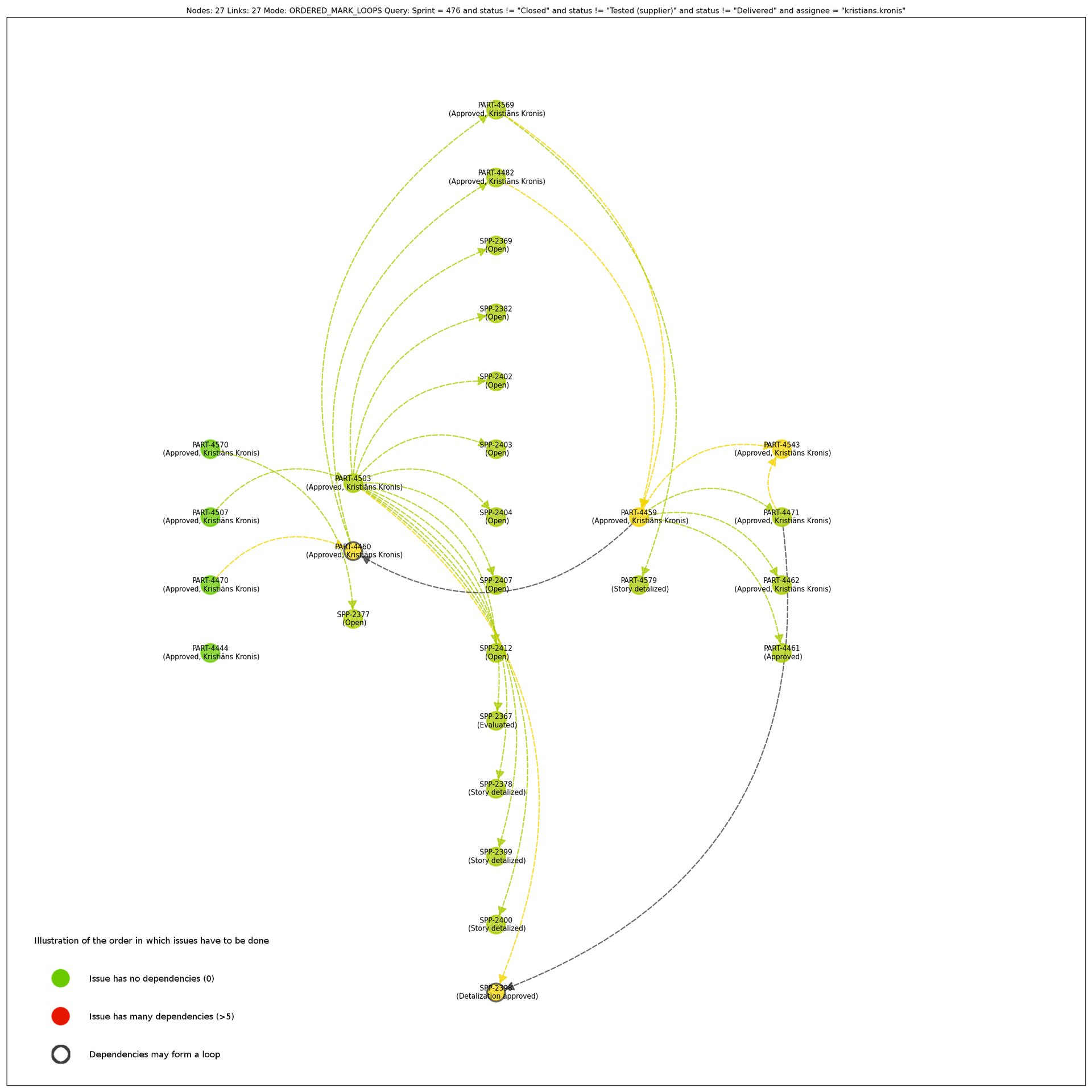
Of course, i do support a variety of different drawing modes that you can check out:
- SIMPLE - will order all of the issues purely by the amount of dependencies they have
- ORDERED - will order the issues, processing all of the dependencies in order (a bit like a Gantt chart)
- ORDERED_MARK_LOOPS - same as above, but will also attempt to highlight loops
The picture above uses the last one, which i created to attempt highlighting badly developed issue links and dependencies. Essentially, sometimes issues have unnecessary dependency links. For example, if you have some dependencies that go like this: A -> B -> C, then C depending on A is clearly wrong! You might get situations like that in practice due to bad system planning or design, but for the most part this should simply indicate that your dependencies need more work.
Personally, i find that this tool has helped me identify situations both like that, as well as figure out blockers ahead of time. In the image above only either my own issues or the ones that depend on them are visualized, however in practice you'll often get situations in which another person needs to finish their issues first, before you can start working on yours.
Further considerations
Of course, this sort of a tool might also indicate flawed planning processes. If i as a developer happen to look upon a sprint and find that it's not as clear as i'd like, then that most likely indicates that i haven't been brought up to speed in regards to the requirements.
Ideally, before every sprint, meetings should be held in which the requirements are discussed and the actual technical implementation is chatted about amongst the people who'll need to actually develop it. Now, in large enterprises this might not always be the case, but i do believe that brainstorming sessions (even with the clients) could be of great use. In those, the concerns of the team members naturally become visible, for example if you're planning everything out by putting sticky notes on the walls, you'll eventually notice people forming small groups while discussing them, which might coincide with the domains of the system.
Essentially, system architects or business analysts working as a black box to the developers may oftentimes lead to sub optimal outcomes! In addition, requirements engineering should be taken more seriously. Yet, if you cannot change or influence the company culture in any major ways, then tools like the one above might be rather suitable for coping with the organization complexities, clients' requirements being changing and not awfully well organized etc.
Other posts: « Next Previous »