What to do when a disk dies
Date:
For the past few years, I've been running my own hybrid cloud: some of my software runs in the cloud in servers that I rent from Time4VPS, however a lot of my other software (CI nodes, backups, chat applications) is running locally, in my homelab servers.
This is excellent both because it allows me to remain in control of my own data, as well as because it's more affordable when I might have to deal with multiple TB of data - buying a regular 1 TB HDD costs me around 40 euros, whereas getting that amount from the cloud might be far more expensive (even if I get multiple disks for redundancy myself). In addition, it also helps me avoid contributing to e-waste too much, because my homelab servers are running off of my old CPUs and other parts.
However, the downside of this approach is the fact that all of the sudden I'm responsible for keeping everything running. This is a story of one such occasion, when a HDD on one of the servers died. Initially, it looked like it was actually up, with the power LEDs being lit up normally and the PSU fans spinning and whatnot, however a glance at my Zabbix monitoring system revealed the problem:
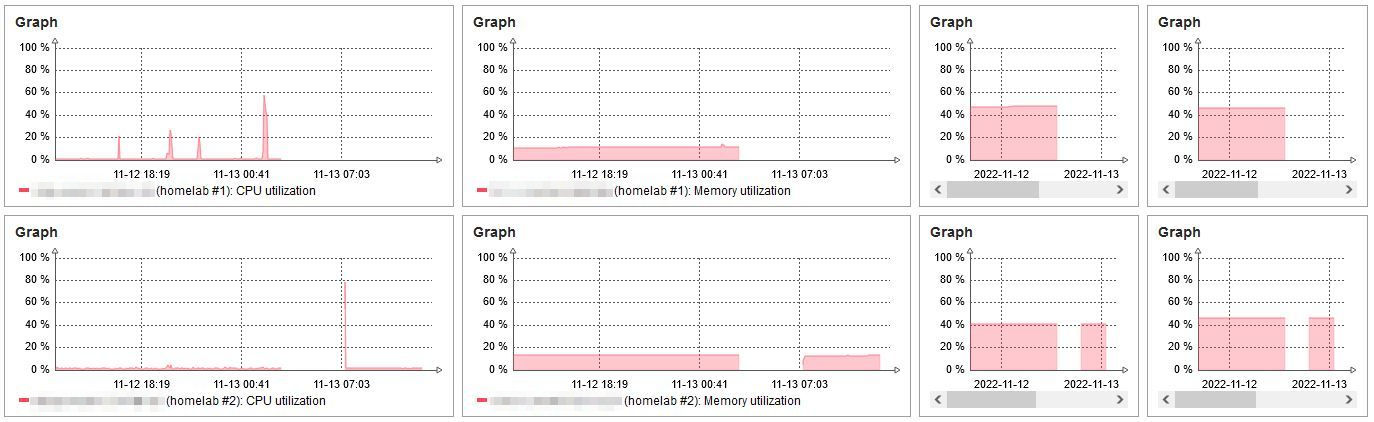
I've scheduled the nodes to hibernate during the night when I sleep and don't need them, however it would appear that one of them didn't start up after one such occasion. It probably has something to do with starting up drawing more power than when the node is up and running idly, but most of the time I've seen such issues manifest themselves right around hibernation or restarts.
Shortly afterwards, my self-hosted instance of Uptime Kuma also sent me a warning to my chat application of choice, Mattermost, as the applications that would normally run on the node were no longer available:
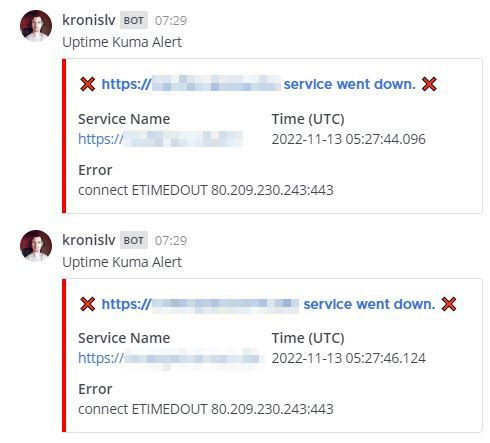
This means that anything that I'd open through a web interface, or that my CI tasks would run against, would be unreachable. The obvious thing here is that if all of the nodes were to go down (or different ones instead), then there's also the risk of the uptime monitoring system going down, or the chat platform also no longer being available, as demonstrated in an example here, where I stopped all of the servers:
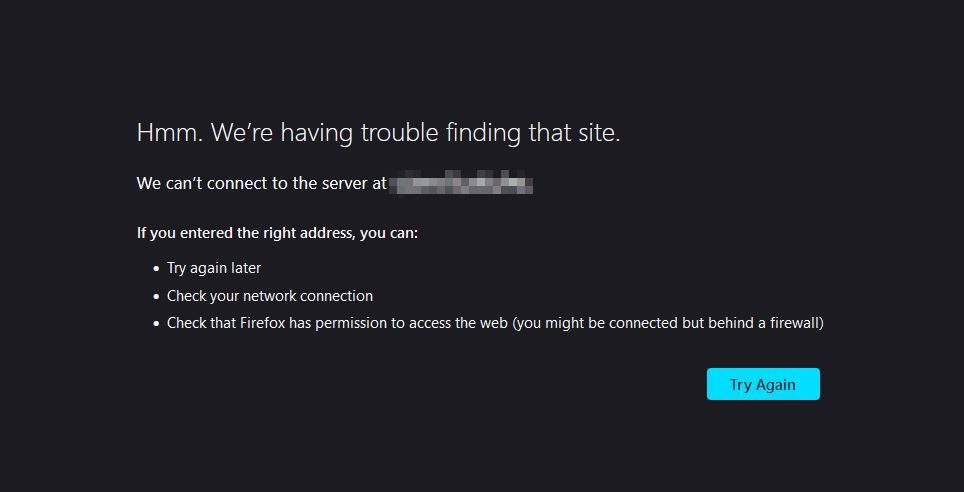
I'd also get the same sort of error in any software that depends on these being up:

However, thankfully the latter would mean seeing that on my devices that are normally connected to the chat system. Not only that, but my infrastructure is also simple enough for me to have little to no issues finding the cause. After doing some disassembly of the servers and connecting a monitor up to the one that actually refused to start, I got a quick idea about what the problem was:

It was revealed to me that there were I/O errors and that one of the disks failed to work properly, which then broke the entire server startup. Personally, I don't really like this, even though I've indicated in my fstab file that errors shouldn't cause the startup to fail, the boot process expects user input regardless after trying to figure out what's wrong with the disk and thus prevents booting and everything else working. But since the amount of disks is small and the disk failures are relatively rare, this is passable, especially because I don't have any critical software running on the nodes.
Also, you can actually see a few SSDs and spare HDDs there, because I've decided that in the near future I'm going to migrate from an EOL version of Debian (which is only kept secure thanks to Debian LTS for now) to Ubuntu LTS because of the seemingly longer life cycle, but that's a story for another day. Regardless, we have an issue, how are we going to solve it?
What can we do to recover data
My first idea is to remove the faulty drive and make a small effort at data recovery. You see, sometimes these HDDs fail when you try to put a whole bunch of load on them during startup but otherwise it's still possible to connect to them and carry the data over. Other times the failures are intermittent but you can otherwise still read the disks, so if you are ready to do lots of retries and don't care about the wear on the disk anymore (given that you'd replace it anyways), it can be a viable way of getting your data over to a new disk.
Since it doesn't take too much effort, I figured that I'd get some of the disk enclosures that I have laying around and would connect them to my laptop and try to pull the data over manually. Sometimes it's better to use a specific distro like Clonezilla for doing something like this, but in my case I just figured that I'd start out with the simplest option and would prod around for a bit:

I connected both the old disk and the new disk to enclosures and then connected those to power sources and an USB hub, which was then connected to the laptop. Sadly, this didn't seem to work, because while the disks spun up, nothing showed up in the OS:
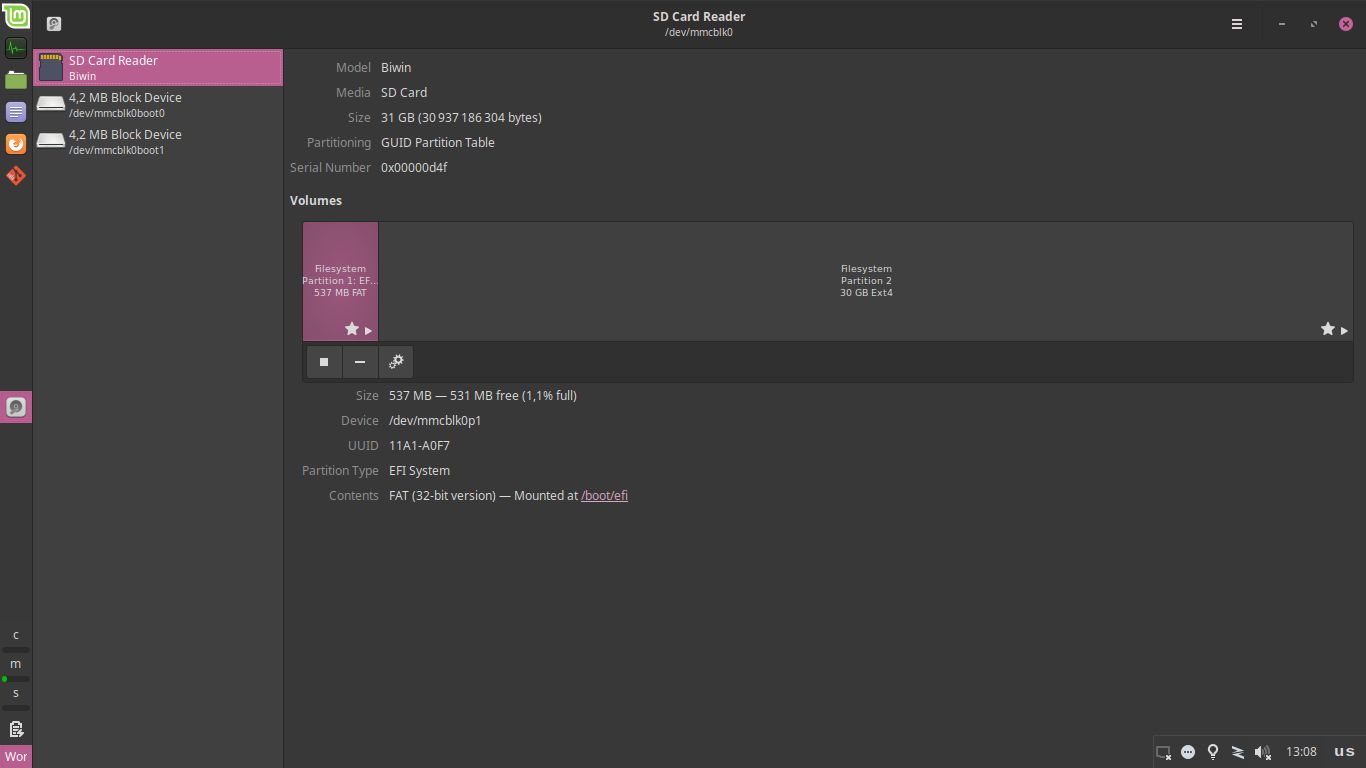
This was also confirmed by me having a look at GParted, the lovely piece of software that I intended to use for partitioning the new drive before carrying the data over, which in this case wouldn't even show me either of the physical devices:
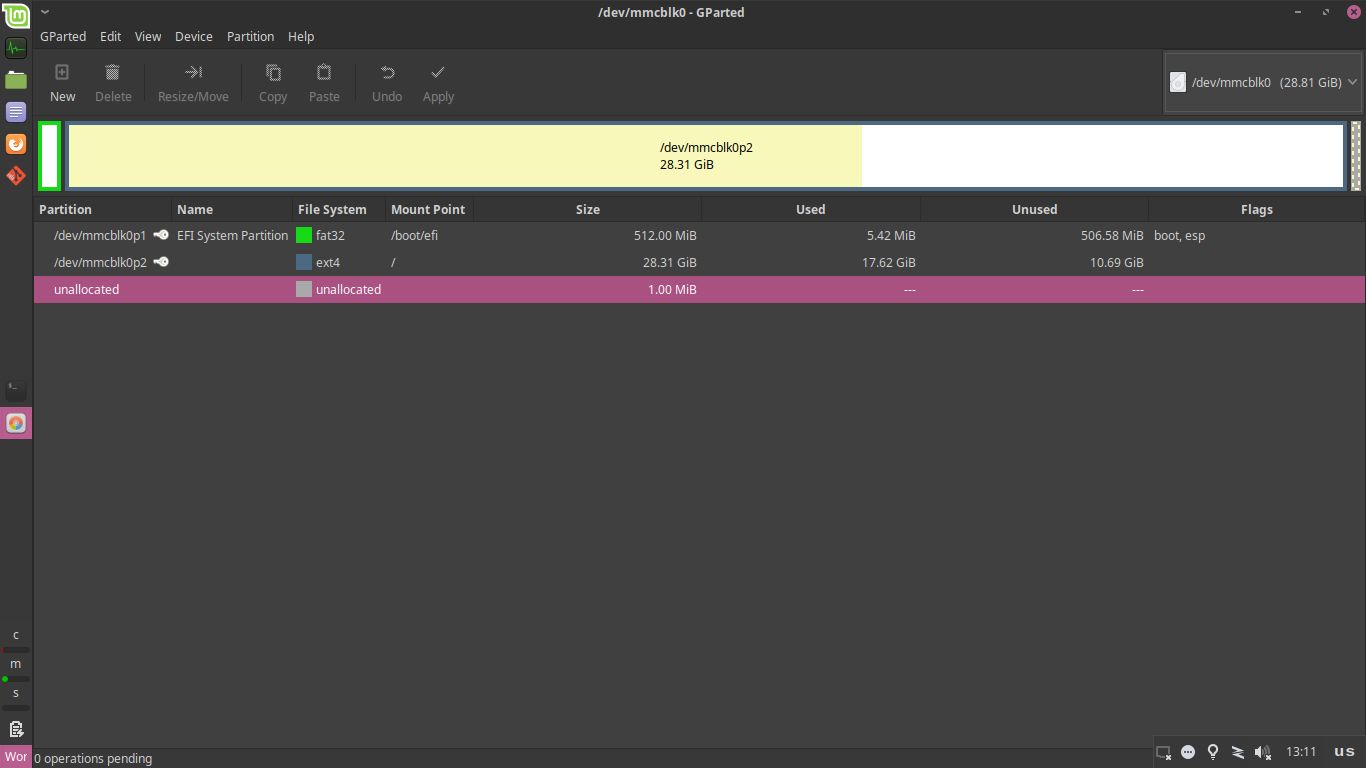
So what gives? Frankly, I wasn't sure here, at first I checked whether the enclosures themselves seemed to work, because I've successfully used them in the past. That seemed to be the case, I got some indication of activity on the disks:

And if I were to go ahead and disconnect the USB connection from my laptop, the lights also turned red to indicate this change, so clearly the enclosure was operating as expected:

Having had bad experiences with USB hubs in the past, I thought that maybe it was to be the problem here. Technically, it shouldn't matter whether I'm connected directly to the laptop, or am using some sort of a hub, or even a daisy chain of hubs (as long as I don't mind a drop in bandwidth), but sadly things rarely make that much sense:

After getting rid of the hub, which I tried with one of the drives, it was detected correctly, which proved that the hub was the problem here:

I'm really not sure why these things keep not working: I've had more luck with plugging a mouse and a keyboard or even mass storage into a monitor which is then connected to the computer, rather than using the standalone USB hubs that you can buy in the stores here. I'm not sure whether it's bad quality or a case of poor abstractions, or something else, but for now I just had to go without the hub.
Regardless, the disks were showing up as expected:
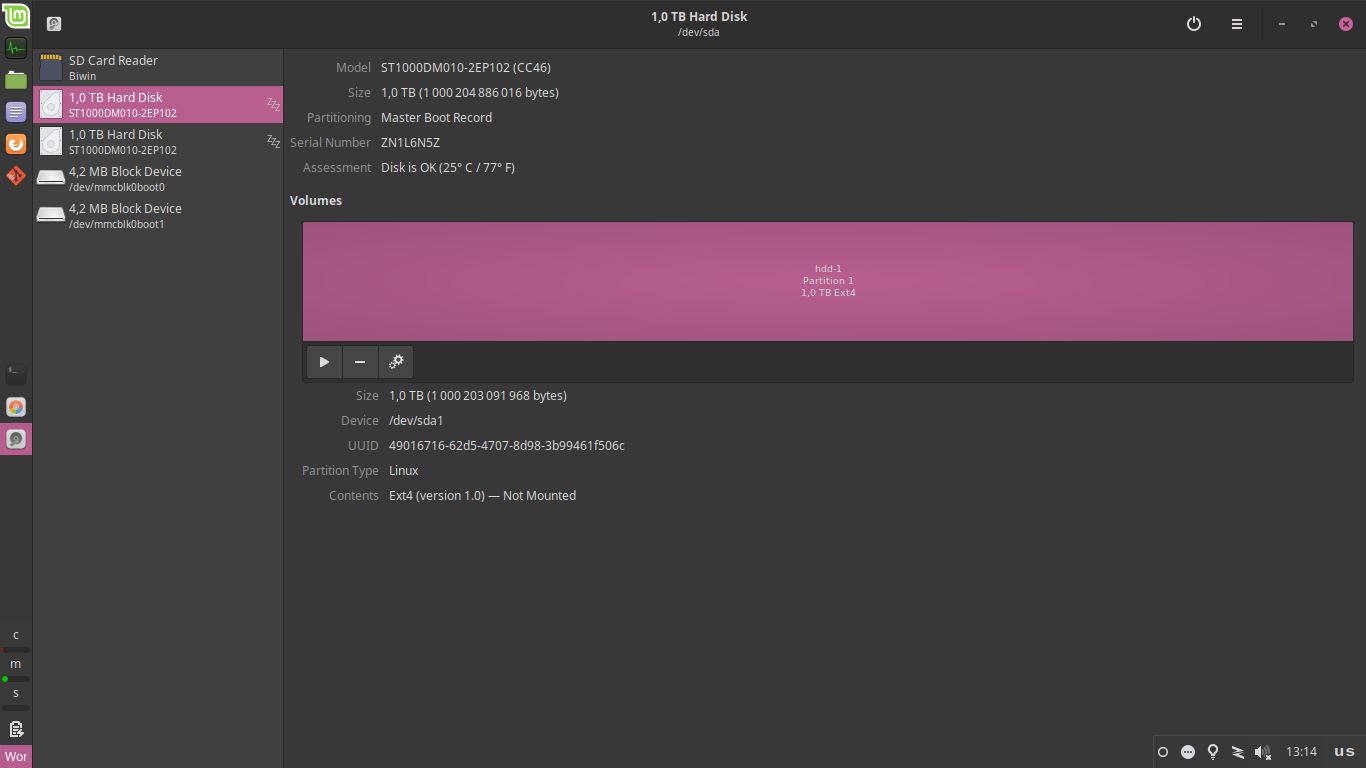
Even if that meant that I had to unplug the mouse and use all of the available USB ports (of which the laptop only has 2, mostly being intended for note taking) for the disks, which looked a bit odd and was slightly worrying because the touchpad has the habit of randomly stopping working:

So, now we have two drives connected to a laptop and can proceed with trying to carry over the data from the old one to the new one.
How can we recover the data
First up, I actually need to initialize the new drive to be able to write some data to it, provided that the old one would let me do that. So, I created a partition table on it, matching the configuration of the old one:
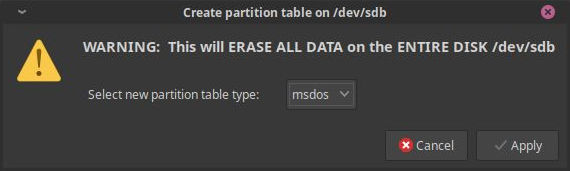
Once that was done, I could actually write partitions to it, which can then be mounted into the OS. In my case, I simply chose a regular ext4 partition that was named the same way as the previous one. Maybe using random strings for disk names would have been better (since hdd-1 on one machine can be a different thing from the hdd-1 on another machine), but for now that's fine:
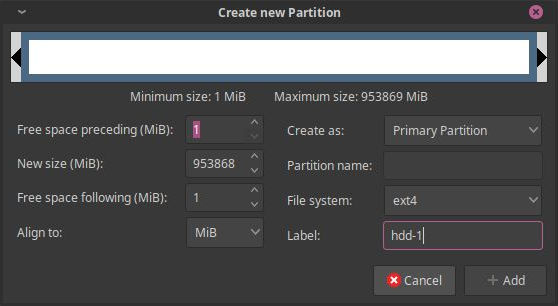
It's nice that I got warnings about potential loss of data, though thankfully I only had to double check that I was working with the correct disk, as there's nothing I can lose on the new one, given that it was empty. Of course, you might also want to have the old drive not be connected altogether to avoid misconfiguration and actual data loss:
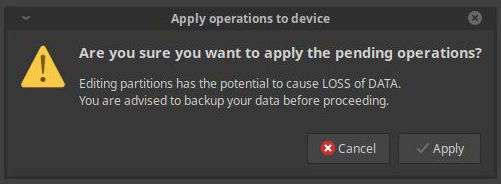
It took a little while to actually create the partition, the process of which went without issues:
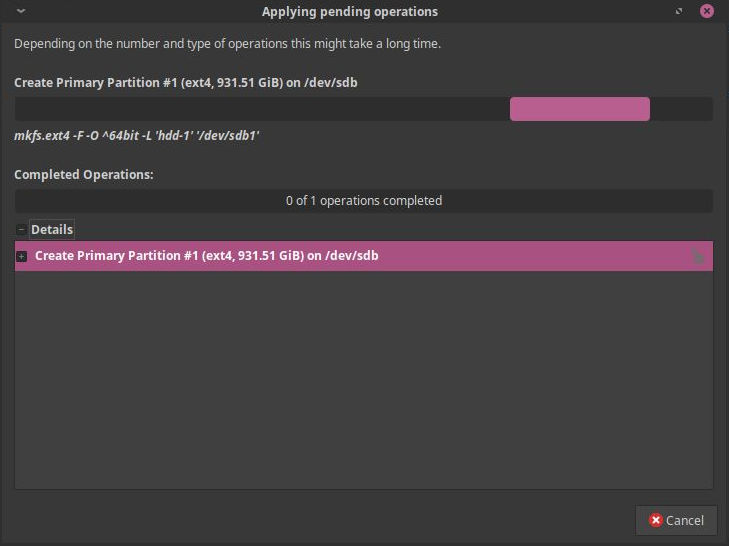
Now, my new disk was ready for having data be put on it, from the old one. The good news here is that my prognosis about the old HDD being usable when not subject to load was correct, I could mount it, open it in the file browser or even read some files from it:
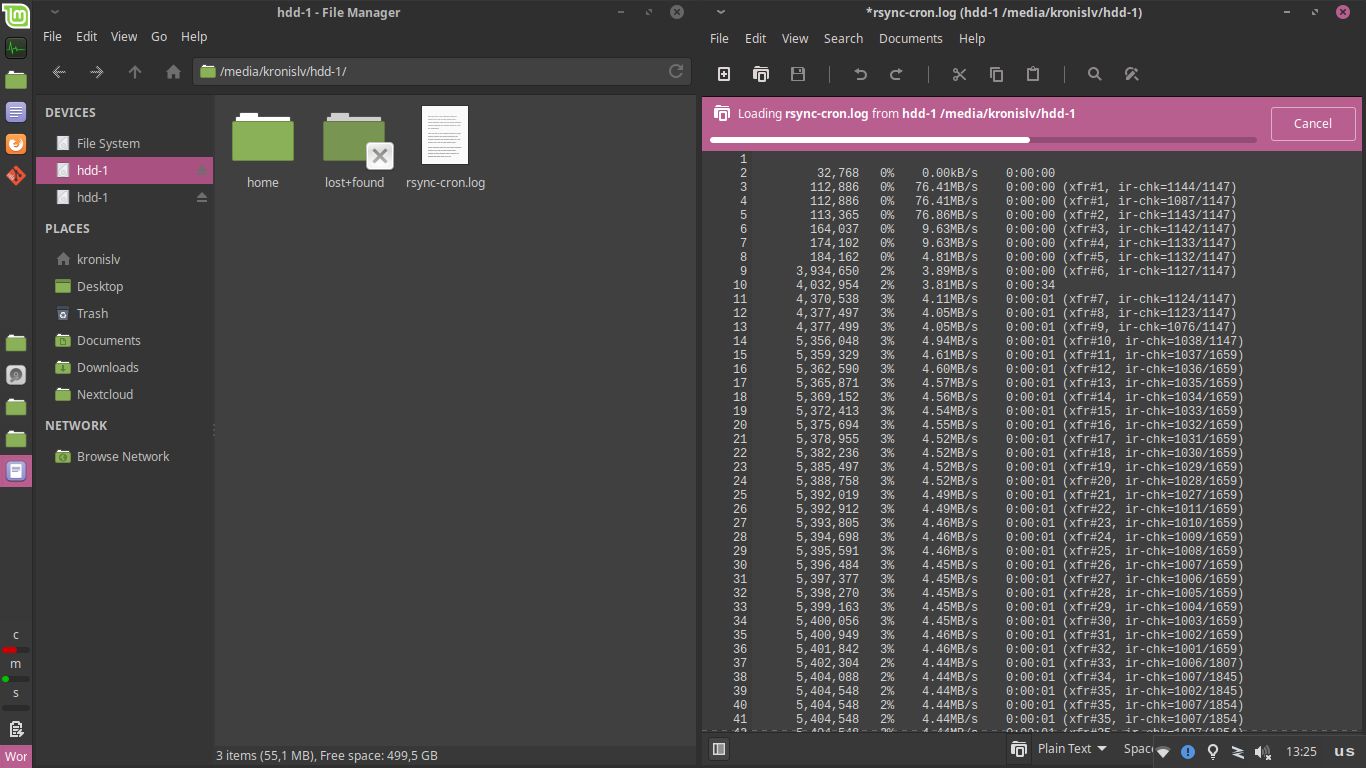
Not too shabby! With that in mind, I set out to use rsync to copy all of the data, while hopefully preserving file ownership information, timestamps and other things, to avoid any surprises. Thankfully, rsync is excellent and has supports doing things like this with ease:

Sadly, this is where my luck ran out. Attempting to copy over the data lead to I/O errors and the same behavior that prevented the server from starting up:
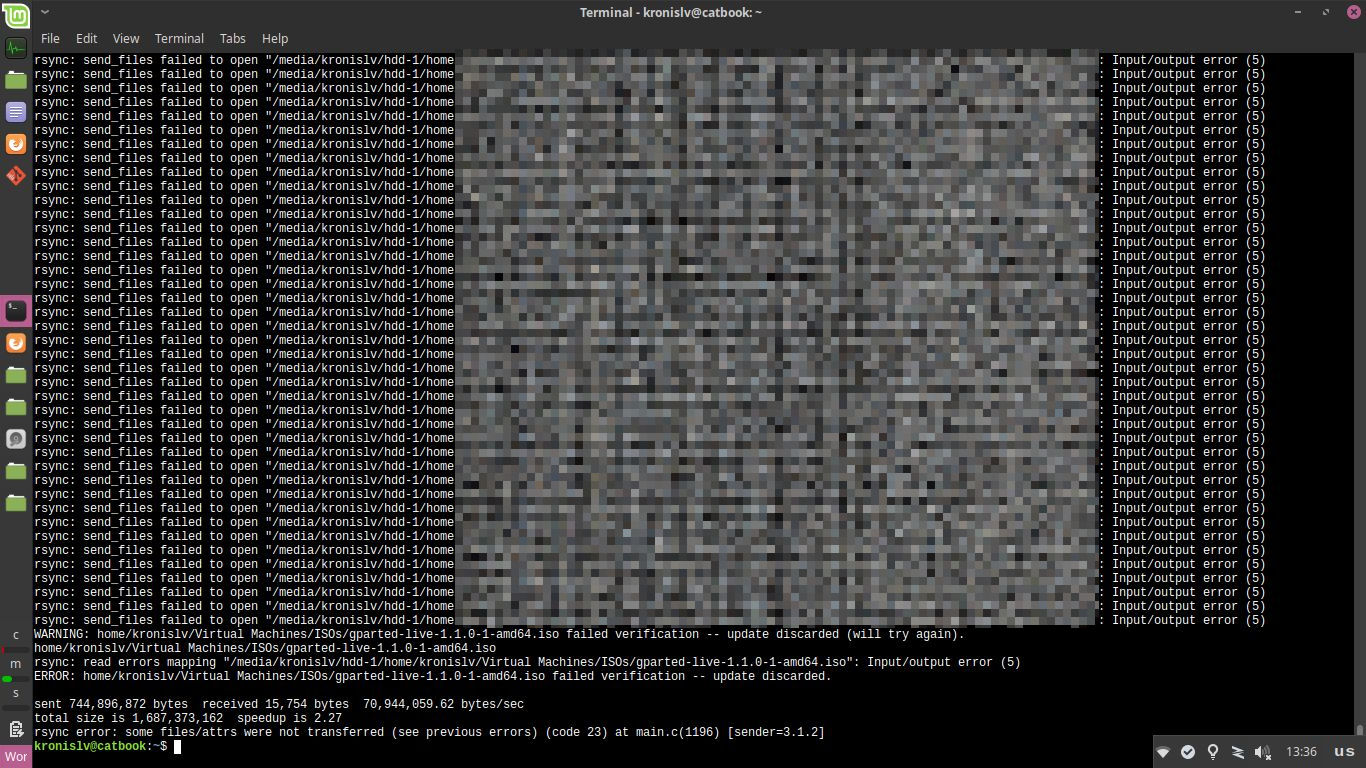
This happened even when I attempted to limit the bandwidth that could be used:
rsync -av --progress --bwlimit=10000 source targetIt was odd, because sometimes it would work for a bit and successfully copy some files, but shortly afterwards it'd fail and the whole disk would disconnect and then reconnect, not being available for a while:
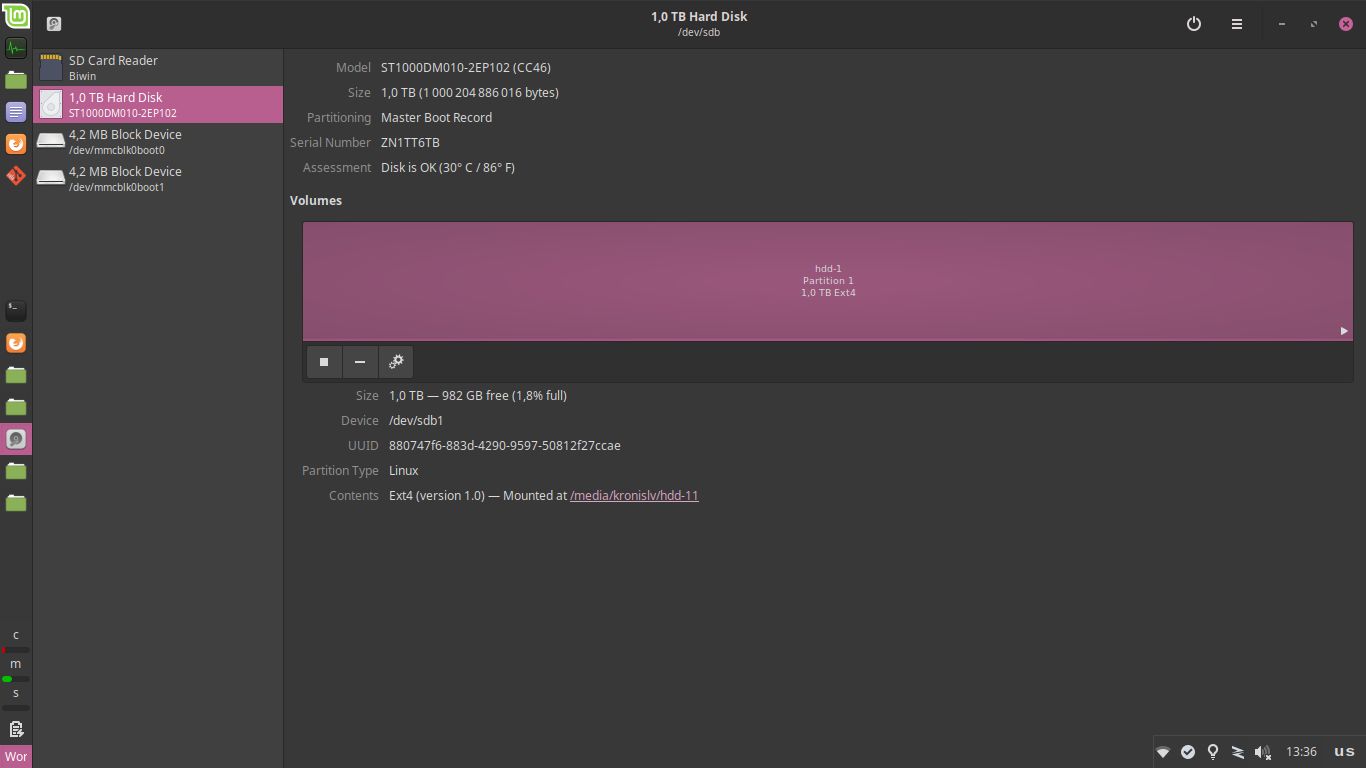
My options here were pretty limited. I could either give up here and look for other options, or attempt to automate retries with no guarantee of success:
- make
rsyncloop until everything is successfully copied, possibly in a Bash script - make the disk automount when it disconnects and reconnects
I've actually done the aforementioned things in the past a few times, but here I wasn't too interested in wasting too much of my time, because I had more coding to do over the weekend. So I went for another option: restoring the data from backups.
What if the data recovery fails
Sometimes, for all intents and purposes, you should no longer look at your disk like a device that you can get information out of, at least without putting too much time, effort or money into it (like trying to do a platter swap and possibly ruining two disks in the process, or paying someone else to attempt the same, which would take lots of time).
Instead, sometimes you should view your disk as an unusable hunk of metal:

You should plan for that happening to any of your disks eventually, given that their lifespan is limited, as is that of any of the data on any one of them. In my case, I simply illustrated this by destroying it, because I will throw the old one out and would prefer that nobody read any of the data on it (which is less of a problem when you use full disk encryption):

So, about those backups... you should definitely have them, from day 1 and also test that they work! Personally, I use something like BackupPC and some other rsync commands that have been set up to periodically execute and copy data either locally or remotely.
This means that I more or less follow the 3-2-1 rule of backups:
- the primary copy of the data I need is on a server, either locally or in the cloud
- then I have incremental and full copies of the data in the backup system locally (compressed and deduplicated)
- that backup data is then copied over to another local disk and then over the local network to another server, for redundancy
It might be a bit more messy than it needs to be (given that I don't have a proper NAS), but so far it has seemed to work okay:
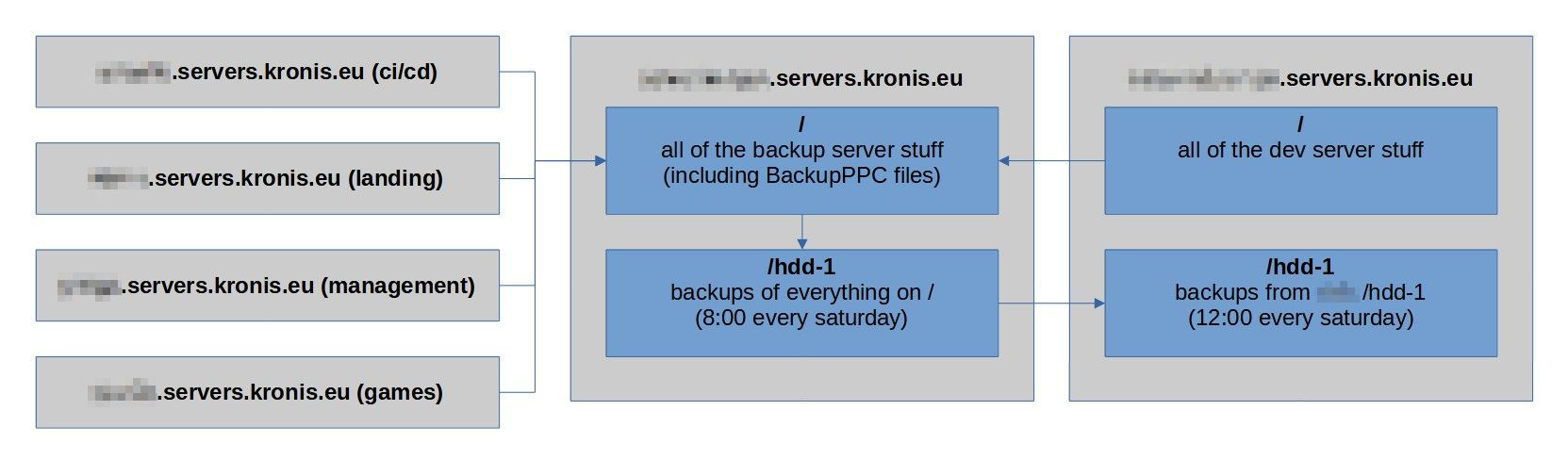
However, in this particular case it all becomes even easier - because the disk that died was simply one of the redundant copies. So what I can do is simply put the new empty disk (with the partition) in the server, boot it up and populate the disk with all of the data as needed, without the backup system itself needing to worry about this.
Except that the server still expects the old disk to be present and fails to start up:
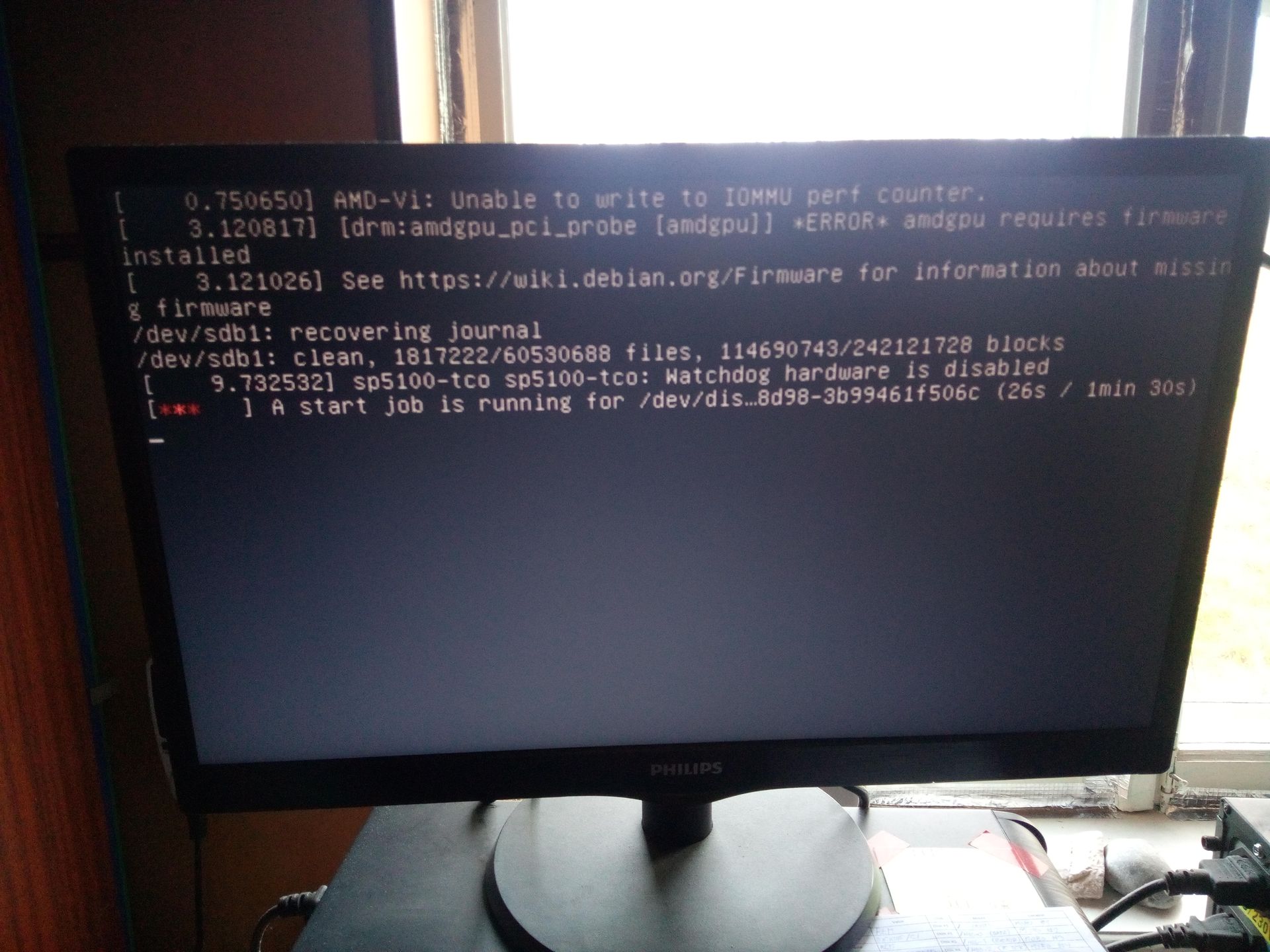
This is because the disk is identified by its UUID (which is different for each device) and thus we need to figure out what it should be changed to, with the lsblk utility:
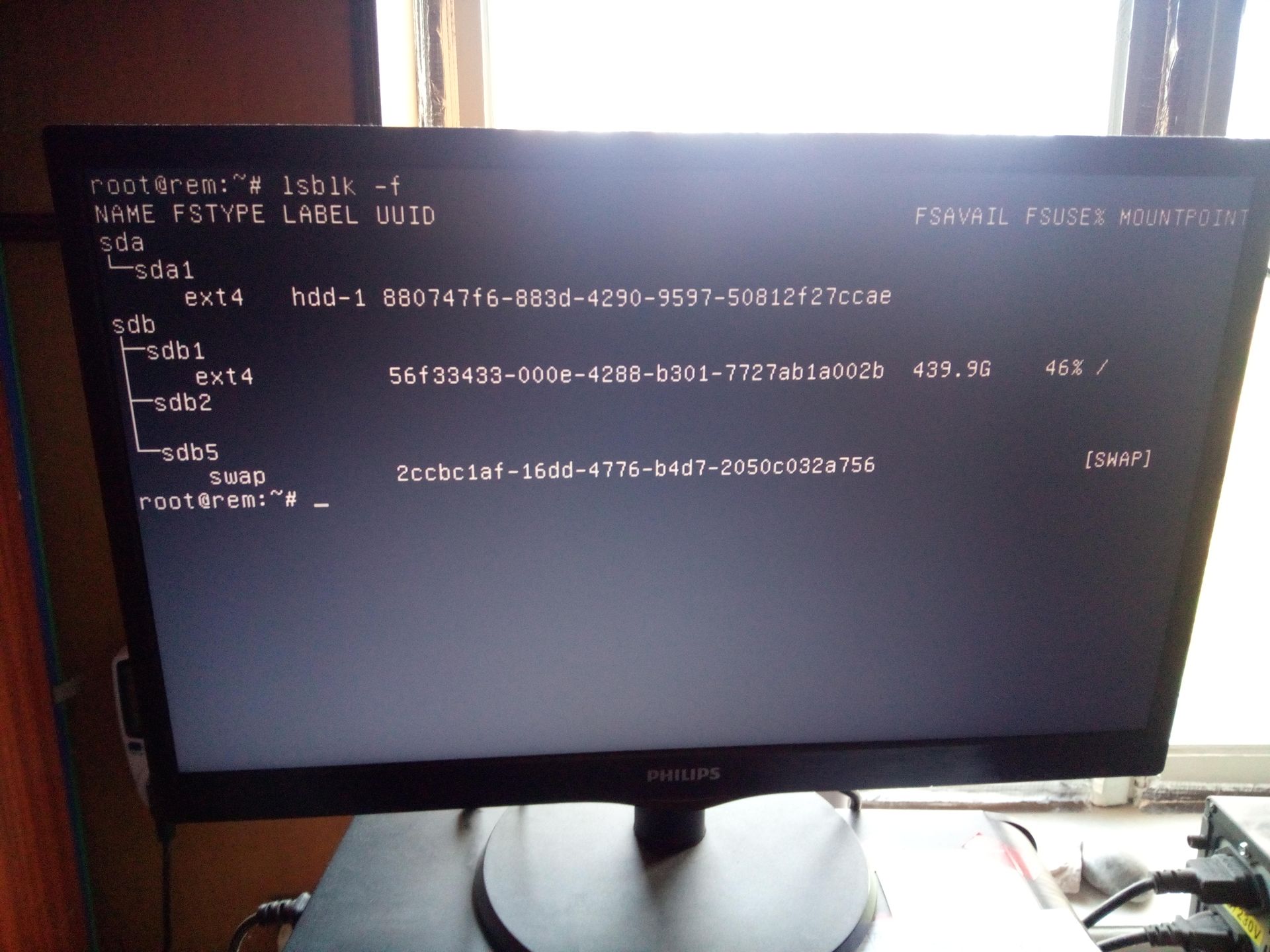
After that, I simply edited the /etc/fstab file with the new UUID and the same old mount point where the previous disk resided:
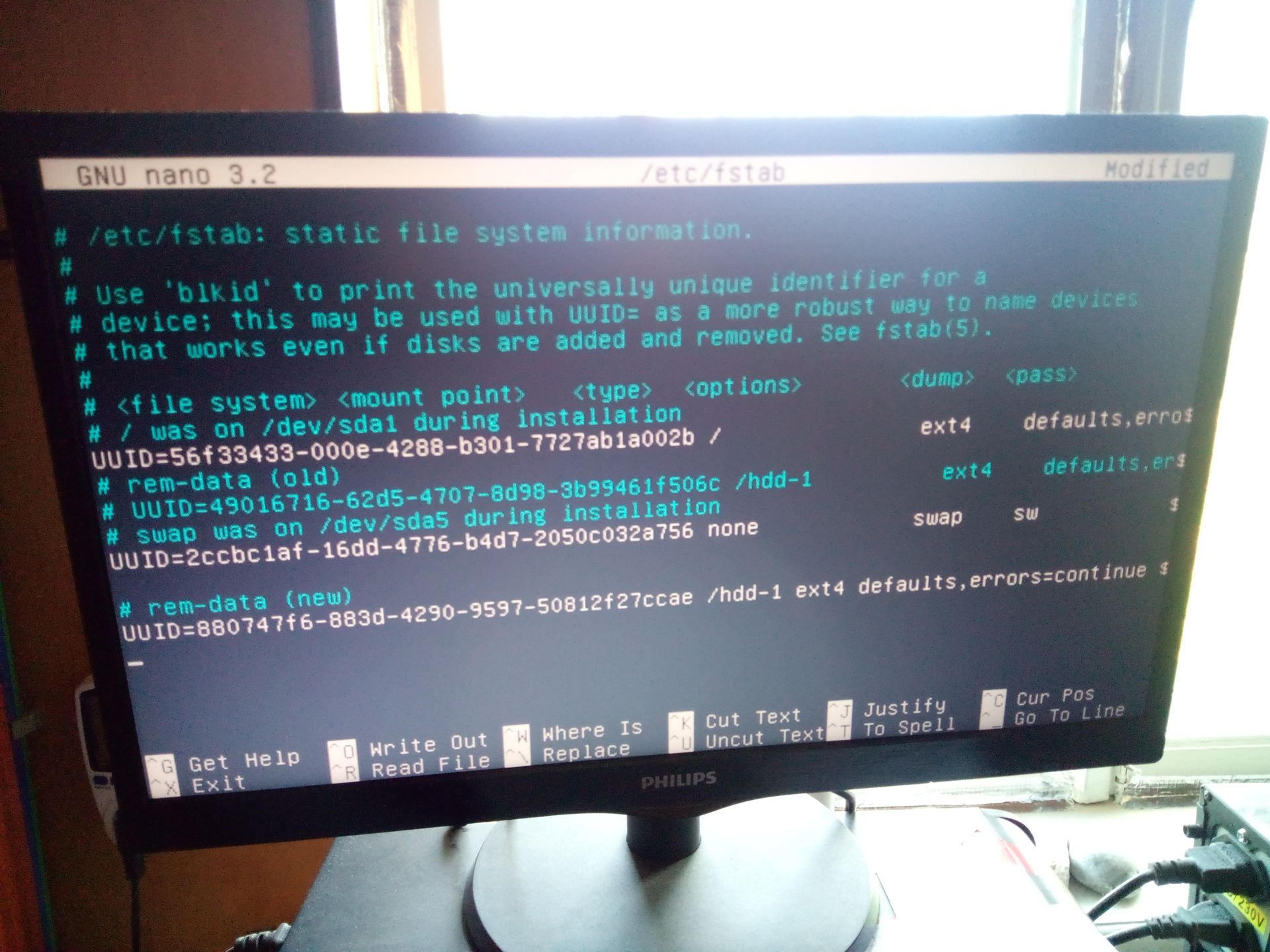
Eureka! Shortly afterwards, the server started up correctly:
After that, I also got the notifications about the services coming back up:
And could also invoke rsync to populate the new disk with data, though admittedly it needed about 500 GB of data to be copied, which took a little while:

In other words, if you plan ahead of time, disks dying won't be the end of the world! However, there are certainly a few things that aren't ideal.
Summary
So what can we learn after all of that?
I'd say quite a few things: first and foremost, these drives failing to mount shouldn't prevent the server from starting up, merely alert me in some way. As for how to actually achieve this, I'm not entirely sure, since errors = continue was just straight up ignored and the server instead booted into maintenance/emergency mode and needed user input. Furthermore, suppose that I move over mounting the drive to some server init script outside of fstab - then what? I'd need to setup some alerting and I don't think Zabbix does that out of the box, whereas setting up new triggers in it would not exactly be a pleasant experience. In other words, there's no guarantee that I could easily find workarounds for this.
Secondly, it feels like we expect drives to just keep working and a drive disconnecting and reconnecting won't have something like rsync look at it happening and decide to try retrying afterwards by default. That is fair, but it would be nice to have some sort of an option for drives that are unstable, without needing to do this in Bash scripts. Also, the fact that a drive dies under pressure is just weird in the first place, I've seen this pattern multiple times in the past, as well as the fact that many issues will happen after restarts.
Either way, backups and redundancy helps. It would be nice to get my affairs in order and have one of those fancy ZFS clusters that people speak of, but perhaps those trade offs aren't quite correct for me at the time, given that all of the resources that are available to me are somewhat limited. I might also just look into software RAID afterwards, though even for that I'd need to use some of the lovely PCI-E to SATA expansion cards that I got off of AliExpress and probably mess around with MOLEX to SATA power adapters, given that my consumer motherboards only have 4 disk slots. Of course, I'm not sure whether that would lead to more or less data loss, since my house burning down due to faulty MOLEX adapters would be decidedly bad for data integrity.
Lastly, whether any of this is worth the time and effort will depend on what you care about. In my case, the replacement drive cost me 40 EUR and a chunk of my day, due to me wanting to document the process and write the blog post. If you were to make 100k a year, using cloud storage for this, or one of those fancy ZFS arrays with proper server hardware, or even an off the shelf NAS makes more sense. The circumstances of someone else are definitely different from mine, even a hardware RAID controller might help many out there. As for my current setup - it's simple enough to allow me to fix things like this when I'm sleepy and not do anything too insane. For now, that is good enough.
Update
You can probably see me blurring some of the server names and other irrelevant information, but that's mostly because it's not important for our particular case here. Trying to hide the server names and whatnot is kind of useless when Let's Encrypt transparency logs exist anyways, so don't worry about me forgetting to blur some of them out in places.
Oh, and also the data copying finished successfully in about 2.5 hours. I might also be interested in further copying that backed up data to the other server as well, which might take similarly long - this is why it's a good idea to do such activities on a schedule automatically, in times when I'm not using the servers as much. Then again, it's also very nice to be able to run any such processes in the foreground and observe the results as they happen.
Other posts: « Next Previous »