Software updates as clean wipes
Date:
After taking a bit of a pause from writing blog articles (due to starting to stream on Twitch), I figured that I might as well continue with some of my article ideas!
So, let's talk about updates today! The simple truth is, that after years upon years of being a software developer and running my own homelab, I still cannot do updates properly, ever. No, not because bumping a Docker (OCI) image tag would be too difficult for me, but because whenever I do that, software tends to fail in the most spectacular ways.
I've actually written about my pain quite a bit previously, so that nobody could dismiss it as just bad luck:
Some of the time, that has actually lead me to explore alternative solutions, such as ditching GitLab (which I still think is a lovely solution), for something like running Gitea, Drone CI and Nexus separately, so that updates and dealing with breakages isn't as painful because of the more limited fallout area: Goodbye GitLab; Hello Gitea, Nexus and Drone
Other times, it has made me reason about how we even got to this mess as an industry and what could possibly be done about it, perhaps utilizing a new and slightly different versioning scheme for our software. Admittedly, it would require a cultural shift towards shipping fewer features or at least more infrequently, which probably isn't feasible, but is still a nice thought experiment: Stable Software Release System
But you know what the common denominator here is? Pain.
The problem with updates
Even if I try to look on the bright side of things, actually it's a bit like having Stockholm syndrome: trying to find good aspects about the software being abusive towards me and refusing to do the one thing I want of it, to actually run without issues.
For example, let's consider a situation I had a while ago, where I had an old version of Nextcloud running, that I wanted to update, to stay up to date in regards to security:

I didn't want or need any new features. All I wanted is to bump the version to have new security patches and updates to the underlying packages that it has. So, something like that should truly be easy to do, right? In my case, all I would have to do is just bump the version to a newer one and let any migrations or other changes trigger:
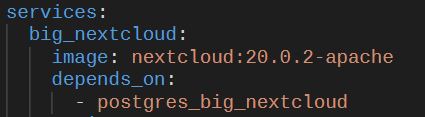
It wasn't even that large of an update, I decided to go from 20.0.2.2 to 20.0.14.2 at first, just to see whether that would work with no issues. Even despite their interesting versioning scheme, that's not jumping major versions, merely installing patches. Also, my setup was exceedingly simple and boring: a regular Docker container that uses the official instructions.
But obviously we can't have nice things, so this update broke:

So, seems like it was messing around with rsync internally and didn't find some random package? But why should that cause the entire solution to break? Why would it be okay for some random SDK that I don't even use to break the entire server?
But oh no, it didn't end there! There were further issues upon container restarts, where it could not find some logging related packages, presumable a new/changed dependency:
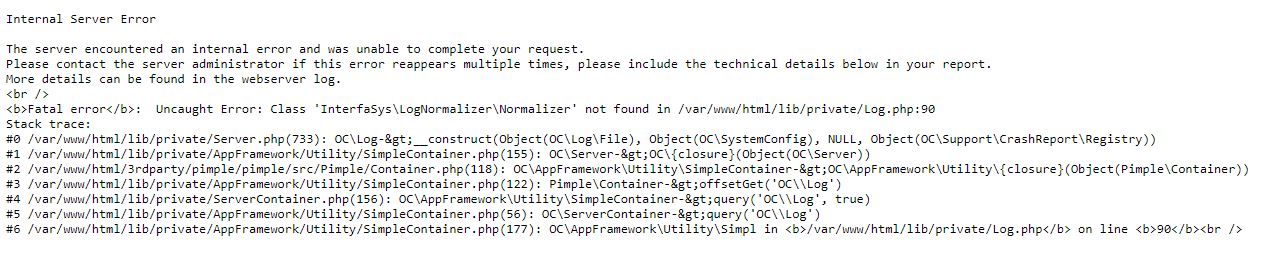
Listen, I could probably rant here all day long about how I wouldn't expect breakages that bad in a patch release and about how having to jump through every single tiny patch release to probably have things break somewhere along the way is unreasonable, should anyone suggest that I do that. But the thing is, I've already brought these things up the previous time this happened... and the time before that.
Updates are hopeless.
You really should have backups
All I could do at this point was to restore the solution from the backup, which I had thankfully gotten pretty good at due to everything breaking:

In case anyone is wondering, the software pictured here is BackupPC: a package that isn't really in (very) active development, but since I have it on my local network and because it works through SSH/rsync and because I host it on my homelab and don't expose it publicly, it's good enough. Especially because of all the deduplication functionality it has, which allows me to have incremental backups for every single one of my servers:
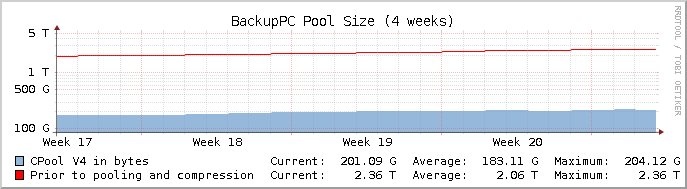
Not only that, but the restore is also a painless process of choosing what you want to restore as in the example above and then just waiting for the task to execute to the end:
But you know what? I shouldn't have to do this. I concede that having backups and restoring them is absurdly powerful, but I also cannot help but to feel that software updates shouldn't be so brittle. Software should be more immutable, if I go from v5 to v6 of some package, surely I should have a way to get the old data model over to the new instance, right?
And yet, it seems like these updates and migrations and file transfers and whatnot still fail. So, what should we do?
What to do about updates
A while ago, I read a lovely article by the name of SQLite As An Application File Format.
It posited that something like SQLite would be a lovely solution for storing most of the data and whatnot for your applications. So rather than directories upon directories of configuration files, using the OS registry (at least in the case of Windows), various directories in the program's own directory or home directory, you'd instead just have one file:
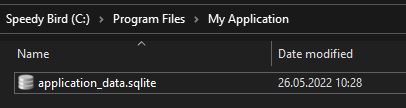
And the more you think about it, the more sense it makes:
- you'd have a standardized solution for most apps to store their data in
- you'd get a lot of power thanks to SQL, which can support both simple and complex use cases
- backups would be incredibly easy, as would swapping out different sets of application data
- you'd benefit greatly from all the amazing testing that SQLite has undergone
For an example of this already working out great, just have a look at the Android ecosystem, where that's just what many apps do!
So, why not do this for most desktop software? Also, why not go a step further? If working with backups is so powerful, why couldn't we explore something like that for these application databases too?
Consider the following example:
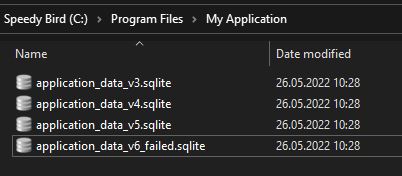
What would happen if each migration of the application data to a newer version would result in a new database file being created and all of the old data being carried over? A sort of ETL pipeline, or maybe even just a copy & paste of the file, running any of the necessary migrations atop of the new one:
def upgrade_to_v5(previous_db: DBFile) -> MigrationResults:
NEW_DB_NAME = "application_data_v5"
new_db = DBFile(NEW_DB_NAME)
copy_db(previous_db, new_db)
return run_new_migrations(new_db)Then, should anything fail, all of our data would still be safe, and we might even save the new DB that failed, with any additional logs explaining the failure. Debugging would be easier. Data would be safer.
Actually, consider that WhatsApp on mobile phones already does periodic backups of the SQLite database:
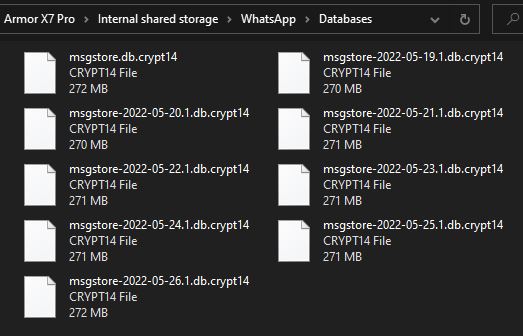
Sure, this does waste a bit of space, but as far as the application is concerned, it only needs to worry about this one database file being up to date. And if it isn't, then upgrading it should be trivial, based on a set of known versions. Suppose you'd have some sort of a schema_version table inside of it, which would tell you that you need to run any number of migrations, depending on the file contents: v4 -> v5 -> v6. And then, it shouldn't matter if the actual app would change, since its files wouldn't be treated as persistent - just run a new container, run the new application on your phone, whatever. No more errors about weird missing vendor packages.
If you want, just back up the actual database, wipe the whole install of whatever software you're running, start up a new version and feed it the data backup, let automated migrations take care of the rest. If containers can be immutable, why can't all of our software also be that way? But sadly, things that make sense aren't for this world.
Why we can't have nice things
For things to work that way and work well, we'd actually need developers to take this sort of approach more often and support it. In my eyes, even MySQL/MariaDB/PostgreSQL would be valid choices for this, since technically we can persist /var/lib/mysql or /var/lib/postgresql/data as well easily enough:

For databases, that seems to work reasonably. But the failure example above with Nextcloud was due to problems with the actual application files, some of which needed to be persistent, according to both the actual docs and common sense: where else would you keep dynamically installed plugins? And yet, even though you could have a separate /plugins folder, somehow most software out there tends to lean towards persisting way too many directories.
So, in practice, you might end up with something like the following:
volumes:
- /home/kronislv/docker/nextcloud/data/nextcloud/var/www/html:/var/www/htmlThankfully, in that regard, at least packages like Nextcloud are getting better, with more fine grained instructions also being available nowadays:
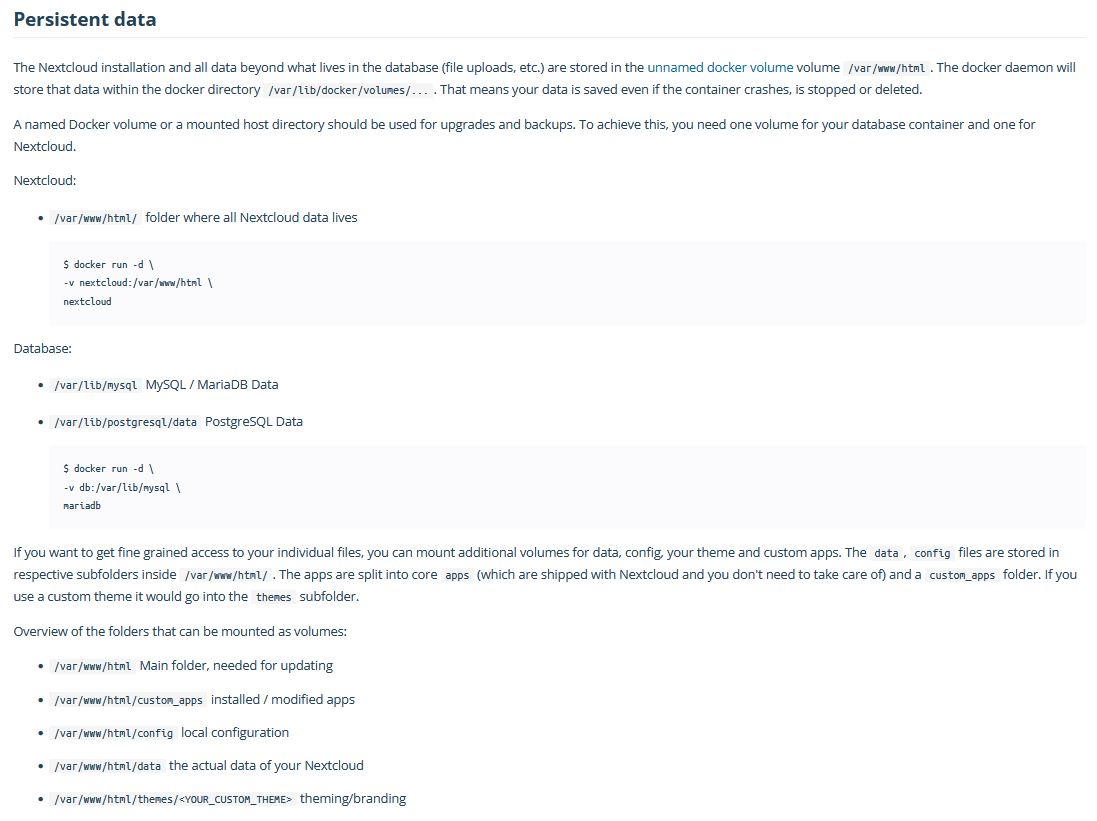
Furthermore, packages like Zabbix also give you a very fine grained explanation of all the separate folders and what they do, for example: https://links.kronis.dev/20v8RdIdnc
But what makes things worse, in my experience, is that everything breaks down because of the evils of HFS, whenever people attempt to stick to its "best practices" and apply systems level thinking to business software: Hierarchical File System
It posits a messy, Eldritch way of laying out file systems which will result in your applications being strewn across a bunch of different folders, making attempts at managing them in a sane way impossible. Now, that might be okay with some set of OS packages that all take advantage of dynamic linking and are interconnected, like various OS tools and bunches of shell scripts that use a variety of those. But it's not a good way to run business software, which I think should always be clearly separated from the OS stuff.
Let's consider what installing something like OpenProject through apt would do to the file system, thanks to a Dockerfile I cooked up:
FROM docker-prod.registry.kronis.dev:443/ubuntu
# Disable time zone prompts etc.
ARG DEBIAN_FRONTEND=noninteractive
# Time zone
ENV TZ="Europe/Riga"
# Let's install OpenProject as an example of HFS evils! First, some preparation.
RUN apt-get update && apt-get install -y gnupg && apt-get clean && rm -rf /var/lib/apt/lists /var/cache/apt/*
RUN wget -qO- https://dl.packager.io/srv/opf/openproject/key | apt-key add - \
&& wget -O /etc/apt/sources.list.d/openproject.list \
https://dl.packager.io/srv/opf/openproject/stable/12/installer/ubuntu/20.04.repo
# Let's do the install and also clean up APT cache after ourselves, to leave only the software on the system.
RUN apt-get update && apt-get install -y openproject && apt-get clean && rm -rf /var/lib/apt/lists /var/cache/apt/*Building it should give us a good idea of how software is installed and managed "the old way":
docker build -t openproject_local_install_test .What we care about here are the underlying changes to the file system, which Docker layers allow us to see, as if diffing the entire file system between two states: before we installed the software and after. Exporting all of the layers and getting to them is actually pretty simple:
docker save openproject_local_install_test > openproject_local_install_test.tar
# extract the layer that you care about, a few tar commands probably go here
winpty docker run --rm -it --mount type=bind,source="C:\Users\KronisLV\Documents\Programming\Projects\layer",target=/layer docker-prod.registry.kronis.dev:443/ubuntu
apt update && apt install tree && cd /layer && tree -L 2 .(curiously, the old -v /source:/target syntax seems to be broken on Windows now)
So, what does that reveal?
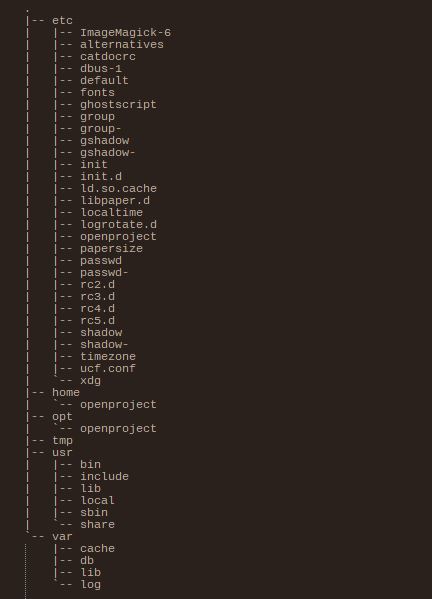
Quite a hefty install tree, as a matter of fact! While it isn't the end of the world, figuring out which of those directories you should preserve can be a bit of a mess:
homeandoptare probably good candidates, because they have anopenprojectfolder; then again, maybe the stuff underoptshould be immutable?tmpandvarseem like they should be rather easy to throw away, so no problems there; hopefullydbandlibare not necessary, or are they?- okay, but surely
etcis related to the dependencies and should be okay to remove? then again, there are.conffiles there, would things break without those? - oh, and don't forget about the many interesting names under
usr, are we really use that only executables are there, not some persistent config?
That's basically what you get when you look in the general direction of HFS and while people will have a few good arguments about why that makes sense for an OS, that makes figuring out how to persist data for business software hell.
Summary
Instead of the mess above, consider the following:
- a single file for all of the persistent data OR clearly defined directories that you know of, like
/dataor even/var/lib/mysql - full immutability for all of the executables, libraries and other dependencies that can change from run to run, or be wholly reset
- the ability to treat every update as a clean install, with an "import" of all of the data from an older schema version/representation
Suddenly backups would be trivial. Persistent storage would be trivial. Updates, even the kind that would break things would be easy to deal with.
Docker already gets us a lot of the way there, with its volumes/bind mounts, even for when you want to store dynamically executed plugins in a folder, not just the config/data. Many modern application stacks also approach immutability in the artifacts, such as deploying a runnable .jar with an embedded web server, versus configuring Tomcat and then launching a .war inside of it. We already have the technology to achieve all of this, we just need to implement this approach more often.
Maybe then my NextCloud updates will actually work and I'll be able to stop making posts every month about some update breaking.
Other posts: « Next Previous »